A few years ago, I gave a talk at NCSU on some work I had done on Littlewood-Richardson numbers, cluster algebras and such things. For the first half hour or so, I outlined the basic results I would be using about the representation theory of the group 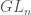 . Afterwards, I had a number of grad students thank me for this. So I’m going to try to turn that into a blog post (and enlarge it a little). The goal here is not to give you any proofs; rather, I want to get to the main results, show you how they connect and, above all, how to actually write down the representations of .
. Afterwards, I had a number of grad students thank me for this. So I’m going to try to turn that into a blog post (and enlarge it a little). The goal here is not to give you any proofs; rather, I want to get to the main results, show you how they connect and, above all, how to actually write down the representations of .
is, of course, the group of 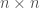 complex matrices with invertible determinant. We want to classify the linear representations of , meaning we want to find group homomorphisms from
complex matrices with invertible determinant. We want to classify the linear representations of , meaning we want to find group homomorphisms from 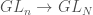 . Some examples: We have the trivial representation, where
. Some examples: We have the trivial representation, where  and every matrix in is mapped to the identity. We have the determinant representation, where again, and
and every matrix in is mapped to the identity. We have the determinant representation, where again, and 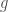 is mapped to
is mapped to  . We have the standard representation, where
. We have the standard representation, where 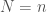 and is mapped to itself. We have the dual of the standard representation, which is given in coordinates by
and is mapped to itself. We have the dual of the standard representation, which is given in coordinates by  . We have the symmetric representations, where acts on the symmetric powers of the standard representation, and the anti-symmetric or exterior representations, where acts on the anti-symmetric or wedge powers of the standard representation. If you have studied almost any field of math, I think it is safe to say that you have frequently encountered these examples; hopefully, that will suggest to you that classifying all representations of is a worthwhile problem.
. We have the symmetric representations, where acts on the symmetric powers of the standard representation, and the anti-symmetric or exterior representations, where acts on the anti-symmetric or wedge powers of the standard representation. If you have studied almost any field of math, I think it is safe to say that you have frequently encountered these examples; hopefully, that will suggest to you that classifying all representations of is a worthwhile problem.
Now, there is a technical point we have to get out of the way. If all we ask for is a group homomorphism, there are far too many. For example, we can use complex conjugation to get maps like 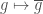 . More confusingly, we can use other field automorphisms of
. More confusingly, we can use other field automorphisms of  , to get highly discontinuous maps. Another way things can get odd is that, as a group,
, to get highly discontinuous maps. Another way things can get odd is that, as a group, 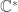 has a lot of automorphisms (at least, if you believe in the axiom of choice), we could compose
has a lot of automorphisms (at least, if you believe in the axiom of choice), we could compose 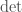 with any of these. Moreover, we could take any of these weird examples and tensor them with a normal example to get more weird ones. So we will want to come up with a rule that excludes these examples and limits us to the more algebraic examples of the preceding paragraph.
with any of these. Moreover, we could take any of these weird examples and tensor them with a normal example to get more weird ones. So we will want to come up with a rule that excludes these examples and limits us to the more algebraic examples of the preceding paragraph.
I’m an algebraic geometer, so my preferred fix is to require that the map 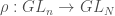 is an algebraic map. This means that every entry of
is an algebraic map. This means that every entry of 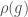 be given by a polynomial in the entries of and
be given by a polynomial in the entries of and 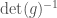 . (In most of the examples I gave of representations, the entries of are polynomials in the entries of , but in the dual representation we need to have
. (In most of the examples I gave of representations, the entries of are polynomials in the entries of , but in the dual representation we need to have 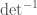 as well.) One of the ways that I would defend my preferred choice is to point out that many seemingly different choices give the same result. You could also require that
as well.) One of the ways that I would defend my preferred choice is to point out that many seemingly different choices give the same result. You could also require that  be holomorphic, and you would get the exact same set of maps. You could (this is the physicists’ choice) study the unitary group,
be holomorphic, and you would get the exact same set of maps. You could (this is the physicists’ choice) study the unitary group,  , and require your maps to be continuous (or, alternately, smooth); then every representation you found would extend uniquely to an algebraic representation of . You could take the definition that I originally gave, using algebraic maps, and run it over any field of characteristic zero, and the description I will give in this post will still be correct. For that reason, I am trying to choose my notation to avoid mentioning the complex numbers whenever possible, although being perfectly consistent about this would be more of a pain than I think it is worth.
, and require your maps to be continuous (or, alternately, smooth); then every representation you found would extend uniquely to an algebraic representation of . You could take the definition that I originally gave, using algebraic maps, and run it over any field of characteristic zero, and the description I will give in this post will still be correct. For that reason, I am trying to choose my notation to avoid mentioning the complex numbers whenever possible, although being perfectly consistent about this would be more of a pain than I think it is worth.
The first thing you need to know about is that it is what is called a reductive group. That means that any finite dimensional representation of splits as a direct sum of irreducible representations. (An irreducible representation is a representation which contains no subrepresentations other than 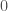 and itself.) This splitting is unique in the appropriate sense, which takes a little effort to state correctly. For an example of a group that is not reductive, consider the group of complex numbers under addition; the representation
and itself.) This splitting is unique in the appropriate sense, which takes a little effort to state correctly. For an example of a group that is not reductive, consider the group of complex numbers under addition; the representation 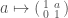 can not be split into irreducible representations. So, we will be done if we can understand the irreducible representations of .
can not be split into irreducible representations. So, we will be done if we can understand the irreducible representations of .
It isn’t just finite dimensional representations that are tamed by reductiveness. If  is any algebraic variety (of finite type over ) and
is any algebraic variety (of finite type over ) and  is an algebraic action of on , then it is easy to show that the coordinate ring,
is an algebraic action of on , then it is easy to show that the coordinate ring, ![\mathbb{C}[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5BX%5D&bg=ffffff&fg=444444&s=0&c=20201002) , of has an ascending filtration by finite dimensional representations. Reductiveness lets us split this filtration, so we get that is an infinite direct sum of finite dimensional irreducible representations. In particular, we can consider the action of on itself. Better, we can consider the action of
, of has an ascending filtration by finite dimensional representations. Reductiveness lets us split this filtration, so we get that is an infinite direct sum of finite dimensional irreducible representations. In particular, we can consider the action of on itself. Better, we can consider the action of 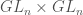 on itself, with one copy of acting from the left and the other on the right. Explicitly, the action is
on itself, with one copy of acting from the left and the other on the right. Explicitly, the action is 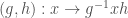 .
.
(Those inverses are not where you expect them because the correspondence between and is contravariant. I’d advise you not to worry too hard about this.)
The Peter-Weyl theorem: the coordinate ring ![\mathbb{C}[GL_n]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5BGL_n%5D&bg=ffffff&fg=444444&s=0&c=20201002) of , as a representation, is
of , as a representation, is 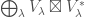 .
.
The sum runs over the isomorphism classes of irreducible representations of . I prefer to rewrite the summand as 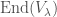 . (Note that the Wikipedia link, at least today, states this result in the analytic setting rather than the algebraic one. This is just another example of how which category you work in doesn’t matter very much for reductive groups.) If you have seen some representation theory, then you should be familiar with Peter-Weyl theorem in the setting of finite groups, where it states that the regular representation decomposes in this manner.
. (Note that the Wikipedia link, at least today, states this result in the analytic setting rather than the algebraic one. This is just another example of how which category you work in doesn’t matter very much for reductive groups.) If you have seen some representation theory, then you should be familiar with Peter-Weyl theorem in the setting of finite groups, where it states that the regular representation decomposes in this manner.
Let’s take an easy example. If  , then
, then ![\mathbb{C}[GL_1]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5BGL_1%5D&bg=ffffff&fg=444444&s=0&c=20201002) is
is ![\mathbb{C}[t, t^{-1}] = \bigoplus_{j=-\infty}^{\infty} \mathbb{C} t^{j}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5Bt%2C+t%5E%7B-1%7D%5D+%3D+%5Cbigoplus_%7Bj%3D-%5Cinfty%7D%5E%7B%5Cinfty%7D+%5Cmathbb%7BC%7D+t%5E%7Bj%7D&bg=ffffff&fg=444444&s=0&c=20201002) . The irreducible representations of
. The irreducible representations of 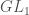 are indexed by the integer
are indexed by the integer  ; the
; the 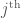 representation is
representation is 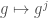 .
.
There are two good ways to use the Peter-Weyl theorem to describe the representation of .
The first, analogous to the use of characters in the representation theory of finite groups, is to look at those functions on which are invariant under action of the diagonal. (I just realized that the word “diagonal” is ambiguous. I am talking about functions which are invariant under the subgroup 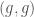 of .)
of .)
On the one hand, these are the functions  such that
such that 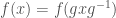 . In other words, functions which depend only on the conjugacy class of their input. Now, the diagonalizable matrices are dense in , so any function on is determined by its values on the diagonalizable matrices. Furthermore, if is to be a conjugacy invariant function, then the value of on diagonalizable matrices is determined by its value on diagonal matrices. So we can describe such an by giving its value on
. In other words, functions which depend only on the conjugacy class of their input. Now, the diagonalizable matrices are dense in , so any function on is determined by its values on the diagonalizable matrices. Furthermore, if is to be a conjugacy invariant function, then the value of on diagonalizable matrices is determined by its value on diagonal matrices. So we can describe such an by giving its value on  . Finally, note that
. Finally, note that 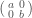 is conjugate to
is conjugate to 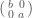 ; more generally, conjugation can reorder the entries of a diagonal matrix arbitrarily. So must be a symmetric function of the
; more generally, conjugation can reorder the entries of a diagonal matrix arbitrarily. So must be a symmetric function of the 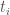 . Moreover, since we are working with algebraic maps and algebraic functions throughout, must be a symmetric Laurent polynomial in the . Conversely, any symmetric Laurent polynomial gives a conjugacy invariant polynomial function on .
. Moreover, since we are working with algebraic maps and algebraic functions throughout, must be a symmetric Laurent polynomial in the . Conversely, any symmetric Laurent polynomial gives a conjugacy invariant polynomial function on .
On the other hand, from the presentation ![\mathbb{C}[GL_n] = \bigoplus_{\lambda} End(V_{\lambda})](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5BGL_n%5D+%3D+%5Cbigoplus_%7B%5Clambda%7D+End%28V_%7B%5Clambda%7D%29&bg=ffffff&fg=444444&s=0&c=20201002) , we see that each irreducible representation
, we see that each irreducible representation 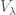 contributes a single basis element
contributes a single basis element 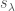 to the diagonal invariants in . (Namely, the identity map from to itself.) Explicitly,
to the diagonal invariants in . (Namely, the identity map from to itself.) Explicitly, 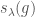 is the trace of acting on . For example, the standard representation gives us
is the trace of acting on . For example, the standard representation gives us 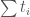 and the dual of the standard representation gives us
and the dual of the standard representation gives us 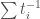 . The symmetric functions are called Schur functions; by the discussion of the previous paragraph, the Schur functions are a -basis for the symmetric Laurent polynomials.
. The symmetric functions are called Schur functions; by the discussion of the previous paragraph, the Schur functions are a -basis for the symmetric Laurent polynomials.
Now, there is an obvious basis for the symmetric Laurent polynomials, namely, the monomial symmetric functions. There is one of these for each decreasing  -tuple of integers,
-tuple of integers, 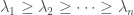 . We just take the sum
. We just take the sum 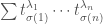 where
where  ranges over the permutations of
ranges over the permutations of  .
.
So, on some intuitive level, we expect that there is one irreducible representation for each such -tuple 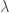 . The idea which makes this precise is the idea of high weight vectors. If
. The idea which makes this precise is the idea of high weight vectors. If  is a representation of then
is a representation of then  is called a high weight vector if
is called a high weight vector if  is fixed by every upper triangular matrix with
is fixed by every upper triangular matrix with  ‘s on the diagonal.
‘s on the diagonal.
Theorem 1: In every irreducible representation, up to scaling, there is a unique high weight vector.
For example, in the standard representation, 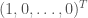 is the high weight vector. It is also easy to check that the diagonal matrices send high weight vectors to themselves. So, if is an irreducible representation and its high weight vector, then
is the high weight vector. It is also easy to check that the diagonal matrices send high weight vectors to themselves. So, if is an irreducible representation and its high weight vector, then  for some .
for some .
Theorem 2: In the above setting, we always have . Conversely, for decreasing -tuple of integers, there is a unique irreducible representation such that the high weight vector transforms in this manner.
Now you know a set which is in bijection with the irreducible representations. But I promised I’d tell you how to write them down. The way to do this is the second good way to use the Peter-Weyl Theorem. We introduce the notation  for the group of upper triangular matrices with ‘s on the diagonal. So Theorem 1 tells us that, if we take
for the group of upper triangular matrices with ‘s on the diagonal. So Theorem 1 tells us that, if we take 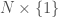 invariants in , we get
invariants in , we get 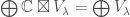 .
.
Now invariant elements of wind up corresponding to functions such that  whenever
whenever 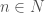 . Some obvious functions with this property are the coordinate functions on the bottom row of our matrix: namely,
. Some obvious functions with this property are the coordinate functions on the bottom row of our matrix: namely,  , …,
, …, 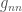 on . More subtly, any bottom justified minor is invariant under left multiplication by . For example, if
on . More subtly, any bottom justified minor is invariant under left multiplication by . For example, if 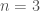 and we write coordinates on
and we write coordinates on 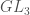 as
as
 ,
,
then the determinant 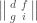 is left -invariant.
is left -invariant.
In fact, these determinants, along with  , generate the ring of left -invariants in . There are many proofs of this, my favorite is Theorem 14.11 of Miller-Sturmfels.
, generate the ring of left -invariants in . There are many proofs of this, my favorite is Theorem 14.11 of Miller-Sturmfels.
So, the ring generated by these determinants is 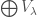 . How do you write down an individual ? You can extract this from everything I’ve said, but I’ll just tell you the answer. is the vector space spanned by products which use
. How do you write down an individual ? You can extract this from everything I’ve said, but I’ll just tell you the answer. is the vector space spanned by products which use 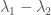 determinants of size ,
determinants of size , 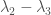 determinants of size
determinants of size  and so forth, up to
and so forth, up to 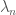 determinants of size . (Note that may be negative.)
determinants of size . (Note that may be negative.)
(The statement that this recipe works is essentially the Borel-Weil Theorem in the algebraic category. More specifically, let  be the group of upper triangular matrices. We showed that the space of functions on
be the group of upper triangular matrices. We showed that the space of functions on 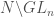 which transform in a certain way under the diagonal matrices is the vector space . Borel-Weil says that the sections of a certain line bundle on
which transform in a certain way under the diagonal matrices is the vector space . Borel-Weil says that the sections of a certain line bundle on 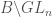 is the same vector space. The equivalence between these two viewpoints, compared to what came before, is not bad.)
is the same vector space. The equivalence between these two viewpoints, compared to what came before, is not bad.)
Let’s wrap up with an example: we’ll take and 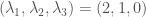 . We must look at products which use one determinant of size one and one determinant of size two. Using the coordinates on above, we need to look at the vector space spanned by
. We must look at products which use one determinant of size one and one determinant of size two. Using the coordinates on above, we need to look at the vector space spanned by
 ,
, 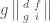 ,
,  ,
,  ,
, 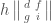 ,
, 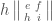 ,
,  ,
,  and
and  .
.
These are 9 products here, but they span a vector space of dimension 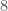 because
because
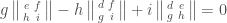 .
.
Choose 8 of these products to get a basis, and it is no trouble at all to write down 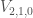 . In particular, it is easy to compute the Schur function
. In particular, it is easy to compute the Schur function 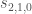 ; it is
; it is
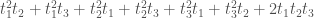 .
.
As a final remark, there is no completely natural way to choose 8 of the 9 products above, and this problem only becomes worse as grows. There are some nice ways though, and one of the simplest is described in Corollary 14.9 of Miller-Sturmfels. An alternate way is the subject of my recent note with Kyle Petersen and Pavlo Pylyavskyy.

Hey, I’m guessing you didn’t meant what you wrote in the first line of the second paragraph …
… and I meant to type something grammatically correct just now.
On other typos, it’s probably a good idea to get your advisor’s name right.
Incidentally in the U(n) setting it’s enough to ask that the representation be measurable; then it will automatically be continuous, smooth, real algebraic…
Thanks for the corrections!
David,
You should submit this post to the next Carnival of Mathematics.
I just noticed this on a second pass: is it a dialect thing to say “high weight” instead of “highest weight”?
We call it “Davidish.” It is distinctive yet quite intelligible.
Thanks for this post, David. It’s quite telling that the grad students at NCSU thanked you for talking about the reps of GL(n). Everyone should know about them (at least the finite-dimensional algebraic ones), and the results aren’t all that hard to state, but somehow they’re not taught in the required grad courses, most place. I think blog are a great place to explain chunks of important mathematics like this, emphasizing intuition but not giving full proofs. I guess that Japanese Encyclopedia of Mathematics and the Wikipedia are two of the few other places one can find such explanations.
Thanks John!
Very well written and interesting article, thank you!
Thanks for this post. , and other 0 in your construction, we get the p-th symmetric power of V,
, and other 0 in your construction, we get the p-th symmetric power of V,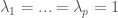 and other 0 we get p-th exterior power,
and other 0 we get p-th exterior power,
Is it true that if we take
and for
so that both these representations are irreducible?
Yup, that’s exactly right.
Sorry for a naive question (I’m quite new to this level of algebra) but could you elaborate on “the coordinate ring,![\mathbb{C}[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5BX%5D&bg=ffffff&fg=444444&s=0&c=20201002) , of
, of  has an ascending filtration by finite dimensional
has an ascending filtration by finite dimensional  representations” ? My guess is that the filtration means existence of rings
representations” ? My guess is that the filtration means existence of rings ![\emptyset \subset R_1 \subset R_2 \subset \ldots \subset \mathbb{C}[X]](https://s0.wp.com/latex.php?latex=%5Cemptyset+%5Csubset+R_1+%5Csubset+R_2+%5Csubset+%5Cldots+%5Csubset+%5Cmathbb%7BC%7D%5BX%5D&bg=ffffff&fg=444444&s=0&c=20201002) with $\bigoplus_i R_i/R_{i-1} \cong \mathbb{C}[X]$, but I don’t see what are those rings. Is it something obvious?
with $\bigoplus_i R_i/R_{i-1} \cong \mathbb{C}[X]$, but I don’t see what are those rings. Is it something obvious?
They’re not subrings, just sub-vector spaces with . And
. And 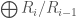 may not be congruent to
may not be congruent to ![\mathbb{C}[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5BX%5D&bg=ffffff&fg=444444&s=0&c=20201002) .
.
For a baby example of the second point, consider the ring![\mathbb{C}[x,y]/(xy-1)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5Bx%2Cy%5D%2F%28xy-1%29&bg=ffffff&fg=444444&s=0&c=20201002) . This has an ascending filtration where
. This has an ascending filtration where 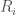 is spanned by
is spanned by  ,
,  ,
,  ,
,  ,
,  , …,
, …,  ,
,  . If we write
. If we write  and
and  for the images of
for the images of  and
and  in
in  , then
, then 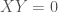 (because
(because  is in $R_0$), so
is in $R_0$), so 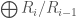 is isomorphic to
is isomorphic to ![\mathbb{C}[X,Y]/XY](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5BX%2CY%5D%2FXY&bg=ffffff&fg=444444&s=0&c=20201002) , which is not isomorphic to
, which is not isomorphic to ![\mathbb{C}[x,y]/(xy-1)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BC%7D%5Bx%2Cy%5D%2F%28xy-1%29&bg=ffffff&fg=444444&s=0&c=20201002) .
.
As for where this filtration comes from: It is always possible to embed into a finite dimensional
into a finite dimensional 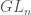 representation
representation  in a
in a 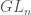 equivariant way. Letting
equivariant way. Letting 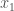 ,
, 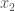 , …,
, …,  be the coordinates on
be the coordinates on  ; the filtration is obtained by taking
; the filtration is obtained by taking 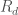 to be the polynomials in the
to be the polynomials in the  ‘s of degree less than or equal to
‘s of degree less than or equal to 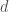 . (Of course, there are probably relations between these polynomials.) I’m tired, so I’ll leave it to you to prove that the embedding
. (Of course, there are probably relations between these polynomials.) I’m tired, so I’ll leave it to you to prove that the embedding  exists.
exists.
Thank you for the post. I’d love to understand how 14.11 in Miller-Sturmfels implies that all of the $Nx1$-invariant polynomials are in the algebra generated by the bottom-justified determinant minors. The theorem in the edition I have says that the collection of these determinants form a sagbi basis for the algebra they generate — why does that imply that all the $N$-invariants are in that Plucker algebra?
Just in case, I posted a question about this on math.stackexchange as well (http://math.stackexchange.com/questions/75617)…
Thanks again!
Or, David, did you perhaps mean Corollary 14.9 from Miller-Sturmfels (semistandard monomials form a vector-space basis for the Plucker algebra)? Then if you already know the dimension of each irreducible representations of GLn, and if you convince yourself that the irreducible representations as found in the coordinate algebra will actually appear in homogeneous components, then you can argue that the Plucker algebra equals the N-invariants algebra by dimension…
Still me. Scratch my previous comment. You couldn’t have meant Corollary 14.9 because you referenced it at the end of your post in a way that’s meaningful to me. So this isn’t a question of typos or different editions of the book.
Is it supposed to be clear at the end how the representations you’ve constructed are related to the known symmetric power and exterior power representations? What does your example rep look like in terms of tensor reps? Do we learn about representations that are not symmetric/antisymmetric powers of the standard and dual rep?
You say we should exclude pathological cases by considering alebraic reprepsentations only, but that these will already include all the continuous representations.
But doesn’t that exclude apparently useful representations like the pseudotensor rep |det g|? In fact, why isn’t this a counterexample to the assertion that the algebraic reps include the continuous ones? It appears to be continuous but not algebraic.
For that matter, what about the example you give, the complex conjugation of the standard representation? Surely complex conjugation is continuous. I mean, it’s continuous in the standard topology. I guess complex conjugation is not continuous in the Zariski topology, but of course the statement “the algebraic maps include the continuous maps” is tautological in the Zariski topology.
As I wrote:
You could … study the unitary group, U(n), and require your maps to be continuous (or, alternately, smooth); then every representation you found would extend uniquely to an algebraic representation of GL_n.
Every continuous representation of U(n) extends uniquely to an algebraic representation of GL_n. For example,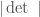 on U(n) extends to the trivial representation of GL_n.
on U(n) extends to the trivial representation of GL_n.
Hi David-
Thank you for the reply and the clarification. I do see now that there is no contradiction. Taking the other example, I think complex conjugation on U(n) extends to the dual representation of GL_n.
But these continuous but non-algebraic representations of GL_n, can they be classified?