It looks like it may be time to roll over the search for narrow admissible sets to a new blog post, as we’re approaching 100 comments on the original thread.
In the meantime, an official polymath8 project has started. The wiki page is a good place to get started. Work to understand and improve the bounds in Zhang’s result on prime gaps has split into three main areas.
1) A reading seminar on Zhang’s Theorem 2.
2) A discussion on sieve theory, bridging the gap begin Zhang’s Theorem 2 and the parameter k_0 (see also the follow-up post).
3) Efforts to find narrow admissible sets of a given cardinality k_0 — the width of the narrowest set we find gives the current best bound on prime gaps.
We started on 3) in the previous blog post, and now will continue here. I’ll try to summarize the situation.
Just recently there’s been a significant improvement in 
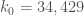
As I write this, the narrowest admissible set of size 34,429 found so far, due to Andrew Sutherland, has width 388,118.
This was found using the “greedy-greedy” algorithm. This starts with some chosen interval of integers, in this case [-185662,202456], and then sieves as follows. First discard 1 mod 2, and then 0 mod p for 
More generally, there are several directions worth pursuing
1. sharpening bounds on 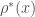

2. finding new constructions of admissible sets of a given size (and also ‘almost-admissible’ sequences)
3. developing algorithms or search techniques to find narrow admissible sets, perhaps starting from a wider or smaller admissible set, or starting from an ‘almost-admissible’ set.
(If these questions carry us in different directions, there’s always more room on the internet!)
For sufficiently small sizes (at most 372), everything is completely understood due to exhaustive computer searches described at http://www.opertech.com/primes/k-tuples.html. At least for now, we need to look at much larger sizes, so obtaining bounds and finding probabilistic methods is probably the right approach.
I’m writing this on a bus, beginning 30 hours of travel. (To be followed by a short sleep then an intense 3 day conference!) So my apologies if I missed something important!

I’m curious about how small k_0 would have to be before it’s possible to do exhaustive searches. Here’s what I’d try. We’re going to try searching the space of all residue classes for primes up to , thought of as a tree. That is, we’ll chose a residue class for 2, and having made that choice one for 3, and so on.
, thought of as a tree. That is, we’ll chose a residue class for 2, and having made that choice one for 3, and so on.
We are then going to sieve out these residue classes, from the interval [0, W], where W is the best known width for the desired cardinality.
Of course, this tree is ridiculously large! (Somewhere around 10^250 for the current k_0.) But two things help significantly. Sometimes, especially for large primes, there are multiple empty residue classes, and so these branches of the tree “glom together”. Second, as soon as the number of elements remaining drops below k_0, we can prune off the entire branch if the tree below. It’s possible that starting with an already good W this will drastically decrease the search space.
I’d be really interested in knowing the running time of such a search! There’s a nice trick for estimating this, by doing random descents down the tree, described beautifully by Knuth in “Estimating the efficiency of backtrack programs” ftp://reports.stanford.edu/pub/cstr/reports/cs/tr/74/442/CS-TR-74-442.pdf
It might also possible to do hybrid searches, which are not exhaustive, starting with a greedy algorithm and switching over at some point to this tree search. In the greedy-greedy algorithm we take advantage of “knowing” that 1 mod 2 and 0 mod p for small p are best, and I’m not sure how to incorporate this idea.
If you could post a link on the wiki page to this new thread it would be good (I don’t have editing privileges).
Will do. in fact I think anyone, as long as they’ve confirmed an email address, can edit the wiki.
I just added a link to the wiki.
Regarding exact computations, Section 4 of the Gordon-Rodemich paper http://www.ccrwest.org/gordon/ants.pdf is on “computing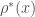 efficiently”. There is also the paper of Clark and Jarvis http://www.ams.org/journals/mcom/2001-70-236/S0025-5718-01-01348-5/S0025-5718-01-01348-5.pdf which computes
efficiently”. There is also the paper of Clark and Jarvis http://www.ams.org/journals/mcom/2001-70-236/S0025-5718-01-01348-5/S0025-5718-01-01348-5.pdf which computes 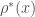 up to
up to  exactly, extending the Engelsma data. I haven’t looked at these two papers in detail though. (
exactly, extending the Engelsma data. I haven’t looked at these two papers in detail though. (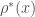 is the largest size of admissible tuple one can fit inside an interval of length x.)
is the largest size of admissible tuple one can fit inside an interval of length x.)
@Scott: the parameter is the square root of the width of the interval.
is the square root of the width of the interval.
Thanks (just a comment to subscribe to comments here).
I have the impression that Drew’s greedy-greedy algorithm (post #77 of the previous thread) seems to perform slightly better when one maximizes a in [0, p-1] in the case of ties, rather than minimizing it.
Applying this on input [-180584, 207398] yields an admissible 34429-tuple with the same end points, hence of diameter 387982.
A simple C implementation of the “greedy-greedy” algorithm described above is available at
http://math.mit.edu/~drew/admissable_v0.1.tar
I have to admit I’m having trouble parsing the algorithm in the Clark and Jarvis paper (In particular Step 3 has two ifs and one otherwise…) But it does look like it has the right ingredients, and presumably takes advantage of both the “glomming” and “pruning” in my comment above.
(small improvement over #6: input [-180568,207406] yields diameter 387974)
Thanks for sharing the code and the output Andrew! It helped me uncover bug in my code (https://github.com/vit-tucek/admissible_sets) I tried to compile and run your program but it didn’t reproduce the output claiming that it did not find admissible set of appropriate size. For larger intervals it segfaulted. I was curious about running time. My implementation of your algorhitm takes around 25 seconds on decent processor and it is pretty high level code so one can experiment easily with different designs. Also the plotting capabilities of matplotlib can maybe help to see what is going on…
I updated the source code listing at
http://math.mit.edu/~drew/admissable_v0.1.tar
to fix a bug that caused a segfault on some inputs (this bug did not affect the correctness of the output).
I also added an optional argument to change how ties are broken, per Wouter’s suggestion (I note that it isn’t always better to break ties in one direction or the other, it’s worth trying both). To reproduce Wouter’s new record type “gg -180568 207406 1”.
@Vit: It takes about 2 seconds (single threaded) on my machine. This can easily be improved to well under 1 second with various optimizations that I took out of the version I posted in order to make it easier for people to follow (these optimizations mattered a lot more when was still 361,460).
was still 361,460).
In the spirit of making a tiny improvement just for the sake of it, I obtained a diameter of 387960 by doing the following. I used the interval [-180568, 207392] and I followed Wouter’s suggestion of maximizing a in [0, p-1] in the case of ties, rather than minimizing it, except for p=1567 in which case I chose a=0 rather than 1202.
I’m fairly sure that this record will be broken soon. But at least I learned a little bit programming.
Using the interval [-205892,182018] and breaking ties upward yields an admissable sequence with diameter 387,910. To reproduce with the program posted above, use “gg -205892 182018 1”.
The sequence can be found at:
http://math.mit.edu/~drew/admissable_34429_387910.txt
Hi!
I just found about about this interesting project and I am still reading up on what you have done.
To test my understanding a bit I would like to ask why this is not a useful admissible set at this point?
http://abel.math.umu.se/~klasm/test-admiss-1.txt
Using the interval [-205892, 182012] and breaking ties upward except for the prime p=1787 yields an admissible sequence with diameter 387904.
@Klas: your set is admissible, but it consists of 1824 elements only. At this moment, we are looking for sets of size 34429.
Here are some further suggestions for the experts in programming:
(Andrew, many thanks for checking my last one, it wasn’t to be…):
On the question about the best class to choose:
to choose:
1) a priori I don’t see any argument in favour of anything deterministic like “min” or “max”. One could try to choose a random one from the set of ‘s defining the tie.
‘s defining the tie.
As this increases the search space, maybe one gets some small improvement.
2) After sieving modulo the primes (say up to the squareroot of interval size):
maybe one should *not* sieve further residue classes but just remove individual integers:
One identifies the set of primes, modulo which the set is not admissible (say bad primes).
identifies the residue classes with least frequency,
but then goes back to the corresponding integers before reduction mod p. Let’s call these bad integers mod p.
Do this modulo several primes (say for simplicity).
for simplicity). ) which are bad modulo
) which are bad modulo 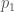 and
and  . Say
. Say  and
and  .
.
Then see if there are integers (say
One can try to remove this “very bad” first.
first. and
and  would have been a waste, as it just intersects in
would have been a waste, as it just intersects in  .
.
Removing the classes
More generally, for those integers surviving the first sieving modulo small primes attach a weight, depending on how bad they behave modulo the bad primes, and remove the very bad integers first.
Comment:
As the product of any two (or more) bad primes is large,
this would seem useless when removing the class 0 mod p.
But at this sieve step we remove other classes as well.
Regarding Christian’s suggestion 1 in post 16, for whatever reason I seem to get better results if I randomly pick either the min or max tied residue class rather than randomizing over all of them.
In any case, here is a sequence with diameter 387814 obtained using the interval [-205796,182018] with the greedy-greedy algorithm and randomly choosing either the min or max residue class when breaking ties:
http://math.mit.edu/~drew/admissable_34429_387814.txt
A slight further improvement on the post above, using the interval [-205754,182012] with diameter 387,766.
http://math.mit.edu/~drew/admissable_34429_387766.txt
It might be worth redoing the older sieves (Zhang’s sieve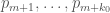 and the Hensley-Richards sieve
and the Hensley-Richards sieve  , or shifted Hensley-Richards ) for the latest value
, or shifted Hensley-Richards ) for the latest value 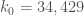 as a benchmark for the most recent improvements. (For instance, by comparing Hensley-Richards with shifted Hensley-Richards one can get some estimation as to the amount of savings that shifting the interval would be expected to provide.)
as a benchmark for the most recent improvements. (For instance, by comparing Hensley-Richards with shifted Hensley-Richards one can get some estimation as to the amount of savings that shifting the interval would be expected to provide.)
In the other direction, the Montgomery-Vaughan large sieve inequality http://www.ams.org/mathscinet-getitem?mr=374060 gives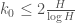 which gives a lower bound of
which gives a lower bound of  without any further improvements in
without any further improvements in  . (This lower bound is unlikely be sharp though.)
. (This lower bound is unlikely be sharp though.)
Given an admissible set, one can try to make it shorter by replacing the endpoints.
For instance, I applied the following to Drew’s interval #18. Let max be the maximal entry of this interval. Then factorize max – j*30030 for j = 1, 2, … until one finds a power of 2 times a large prime, and replace max by max – j*30030.
The factor 30030 = 2*3*5*7*11*13 ensures that we are okay modulo the first few primes. The large prime factor gives us a reasonable chance of surviving, as most of the time we sieved 0 mod p.
Doing this 17 consecutive times results in an admissible set of 34429 elements, of diameter 387570. When one does it 18 times, the result is no longer admissible. If one proceeds by doing the similar thing for the minimum (4 times; 5 times spoiled admissibility) one ends up with an admissible set of diameter 387540. There’s definitely much room for improvement here.
(While typing this I realize that there is no big point in using 30030, in the end.)
While this looks like it may have been superseded by Wouter’s recent improvement, I’ll post this sequence of diameter 387,754 just in case its useful as in input to further optimization
http://math.mit.edu/~drew/admissable_34429_387754.txt
@terry: The optimal Zhang sequence for k0=34429 appears to use m=386 and has diameter 411,932. I can take a look at the other cases this afternoon.
I withdraw my above claim (#21). My resulting set contained duplicates (I thought the Magma function I used took care of that, but apparently it didn’t). Thanks to Drew for pointing this out.
What is the relationship between the diameter and Zhang’s bound? In particular, what would in-principle reaching that H=211,047 imply with k0 fixed? In other words, what is the new bound if your sub-project succeeds and the others fail?
@Andrew: Thanks for working it out! So the more advanced sieving methods are shaving about 6% over the Zhang sieve – a relatively modest savings, but every little bit helps :).
@Daniel: H is the bound on prime gaps, so if we theoretically found an admissible 34,429-tuple of diameter 211,047 (which I doubt), this would imply that there are infinitely many pairs of primes of distance at most 211,047 apart.
Incidentally, the value is likely to be stable for a few days; the process of converting a value of
is likely to be stable for a few days; the process of converting a value of  to a value of
to a value of  is more or less completely optimised now as far as I can tell, and it will take several days more for enough of us to read through the second half of Zhang’s paper to get a confirmed value of
is more or less completely optimised now as far as I can tell, and it will take several days more for enough of us to read through the second half of Zhang’s paper to get a confirmed value of  (though, informally, we’re beginning to suspect that values on the order of 1/300 or so might be achievable, up from the current value of 1/1168, which should improve
(though, informally, we’re beginning to suspect that values on the order of 1/300 or so might be achievable, up from the current value of 1/1168, which should improve  by a factor of maybe sixfold or so, but this is all completely unofficial at this point).
by a factor of maybe sixfold or so, but this is all completely unofficial at this point).
Just to share what I noted to Wouter offline, for most of the sequences I have posted above, it is not possible to improve them by replacing an endpoint with an interior point. Taking the most recently posted sequence with diameter 387754 as an example, there are 790 primes (including all primes less than 4679) for which all but 1 residue class is occupied by elements of the sequence that are not endpoints. If you sieve the interval of just these unoccupied residue classes, there are no survivors that are not already elements of the sequence.
The one exception is the sequence with diameter 387910, the integer 87254 which is not currently in the sequence could be added, and removing the last entry 182018 then reduces the the diameter by 6 (incidentally, I expect this is exactly what happened with the optimization in post 14 which reduced the diameter to 387904).
Up through comment #16 on this post I’ve been able to reproduce the results here with my own code, but with the introduction of the randomization step in #17, I’ve gotten stuck; Drew, if you wouldn’t mind answering a couple of questions about what you’re doing, I’d be appreciative.
(1) When you produced the admissible set in post #17 (to fix an example), did you begin with a guess of the interval [-205796,182018]? Or did you begin with a slightly wider interval (if so, how much wider?), sieve, and then pick the narrowest 34429 elements of the ones that remained? (Unless I’m blundering somewhere, the wider a starting interval I choose the wider the output of the greedy-greedy algorithm seems to be, so there seems to be some art here.)
(2) Given the randomization step, how many times (to an order of magnitude) did you have to run the randomized procedure until you hit the particular admissible set that you found?
With the Montgomery-Vaughan large sieve inequality I only seem to be getting instead of Terry’s
instead of Terry’s  . Sage tells me that in this range sieving up to
. Sage tells me that in this range sieving up to  is optimal, and then the inequality
is optimal, and then the inequality  yields
yields
 .
.
Regarding endpoint issues, one very small step one could take here comes when one has to break ties among residue classes that kill off the same number of survivors; perhaps residue classes that kill off a survivor nearer to (say) the right endpoint are to be favored than ones which stay away from that endpoint, in order to hopefully capture some gain from shifting the interval to the left. (This may also have the side benefit of effectively randomising one’s choice in a way which is reproducible, as per comment #27.) I don’t know how effective this sort of ordering will be though.
Here is the Sage code I used:
k=Integer(34429)
Q=Integer(131)
S=sum([(moebius(q)^2/euler_phi(q)).n(digits=10) for q in [1..Q]])
print k*S-Q^2
@Gergely: there are two large sieve inequalities in Montgomery-Vaughan. The first, easier inequality ((1.4) in their paper) gives the bound you write, but there is a more difficult inequality (1.6) which they use to show that
((1.12) in their paper, or the k=1 case of (1.10)). This together with the prime tuples conjecture already tells us that admissible sets in an interval of length N can have size at most . But the Montgomery-Vaughan argument also works in our setting without prime tuples. From Corollary 1 of that paper we see that we have the inequality
. But the Montgomery-Vaughan argument also works in our setting without prime tuples. From Corollary 1 of that paper we see that we have the inequality
for any . Montgomery and Vaughan pick
. Montgomery and Vaughan pick  and use some standard estimates to eventually bound the RHS by
and use some standard estimates to eventually bound the RHS by  (actually they have a bit of room to spare since they also absorb a
(actually they have a bit of room to spare since they also absorb a  term which we don’t need here). But with the values of
term which we don’t need here). But with the values of  we have here we could perhaps perform the optimisation of
we have here we could perhaps perform the optimisation of  numerically and improve upon 211,047.
numerically and improve upon 211,047.
There is a minor typo in post 22, I should have written m=836, not m=386.
@pedant: Yes, the randomness makes reproducibility a pain, which is one of the reasons I have been posting the sequences (in theory of course the computations are reproducible in the sense that I can give you a program that is guaranteed to *eventually* cough up the sequence, but you might have to be very patient). Regarding your specific questions:
(1) I generally start with an interval that is already about as tight as the best diameter I already know (or even slightly tighter). One advantage of doing this is that it allows you to do an early abort as soon as the number of unsieved integers falls below k_0, and this speeds things up substantially (one can then try again with a slightly shifted interval, effectively covering a larger interval that you could have started with in the first place).
(2) For the sequence in post 17, something on the order of 10^4 iterations. For the sequence in post 22, more like 10^5 or 10^6.
The M-V paper by the way is at http://journals.cambridge.org/download.php?file=%2FMTK%2FMTK20_02%2FS0025579300004708a.pdf&code=aa9418bce94e63604579326df0a7aa58 . And a typo: N should be H throughout to be consistent with our notation rather than M-V notation.
Actually, to be _really_ pedantic, MV’s N is actually H+1 in our notation, rather than H, but I’m sure we can ignore this technicality for now :)
Just a thought that it might be a good idea to publish this problem as a programming puzzle, for example at IBM’s monthly “Ponder This” challenge (http://domino.research.ibm.com/Comm/wwwr_ponder.nsf/pages/index.html). This would open it up to many talented programmers and more computing resources. I sent them a note describing a potential programming challenge finding dense admissable sets, but I’m sure there are other similar forums which might be effective.
I have been doing some experiments with this during the afternoon, trying different ways of constructing admissible sets ( now of the right size too). None of my attempts have managed to improve the currents records but I have noted that it seems to be quite easy to construct sets of the right size and diameters varying between 400 000 and 450 000. More or less every not obviously bad construction method I have tried finds something in that range.
All the methods I have tried are of the form: start with an interval, for each prime delete all remaining numbers in one modulo class, where the modulo class was chosen in different ways.
One robust choice seems to be to pick the modulo class of the largest remaining number in the interval.
Picking the least common modulo class, which might be empty, also works quite well, but produces sets with larger diameter.
These are of course rather crude methods, but I found it interesting that even they don’t land too far from the record holding sets.
@Drew: Thanks! Your answer to (2) explains everything, as my code is an order of magnitude slower than yours and so I haven’t run nearly as many iterations as you have. (-:
(Also, yes, I’ve doing that same abort that you’re doing when the number of unsieved integers falls below k_0.)
For comparison, the Hensley-Richards sieve with
 with
with
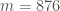 starting at
starting at  to
to  has diameter
has diameter  .
.
@Terry: Thanks for your valuable comments. The improved inequality yields . More precisely,
. More precisely,  and
and  contradicts
contradicts  .
.
@Bryan: This might be a good idea once the polymath8 project plateaus (in particular, once we get consensus on an optimised value of and hence
and hence  ). There is the possibility that
). There is the possibility that  could drop by as much as one further order of magnitude in the weeks to come, which could open up a lot more optimisations than what we are doing right now. By that point we may have some optimised algorithm which may for instance be parallelisable and which could indeed be very amenable to these sorts of challenges.
could drop by as much as one further order of magnitude in the weeks to come, which could open up a lot more optimisations than what we are doing right now. By that point we may have some optimised algorithm which may for instance be parallelisable and which could indeed be very amenable to these sorts of challenges.
To finish of the answer to Terry’s question from post 19, as noted in post 22 the optimal Zhang sequence for k0=34429 appears to have m=836 and diameter 411,932. The optimal Hensley-Richards sequence appears to have m=876 and diameter 402790, and the optimal asymmetric Hensley-Richards sequence appears to have m=811, i=21204 and diameter 401,700.
This suggests to me that there might be a bit more to be gained by shifting the interval around, but not a whole lot.
@Gergely: Thanks! I’ve added a new section on “Benchmarks” on the wiki to record this (and the computations of Andrew and Christian on older sieves). If I read correctly, your calculation did not incorporate a shift by 1 that I noted in #34 (because the set [M+1,M+N] actually has diameter H=N-1 rather than N) so actually the lower bound should be .
.
@Terry: Indeed, I took MV’s for our
for our  . So my bound is really
. So my bound is really 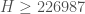 .
.
Er, yes, you’re right, I somehow managed to subtract one off twice. :)
@Bryan: It occurred to me that this problem is a natural for one of Al Zimmerman’s programming contests (or something comparable). But I agree with Terry that it makes sense to wait a while. Also, many of these programming contests are the antithesis of the polymath approach — contestants are usually very secretive about their algorithms and the progress they are making.
@Terry: In the MV bound one can improve to
to 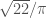 , see Brüdern: Einführung in die analytische Zahlentheorie, page 162. Probably this is in the original paper, too. This buys us
, see Brüdern: Einführung in die analytische Zahlentheorie, page 162. Probably this is in the original paper, too. This buys us  .
.
@Terry
Ok, makes sense to hold off until we nail down k0 further.
@Andrew
Sure some people are secretive but I think just as many work in teams and share work. I guess it depends on the contest / incentives.
@Gergely,
Montgomery (The analytic principle of the large sieve, page 557)
http://projecteuclid.org/DPubS?service=UI&version=1.0&verb=Display&handle=euclid.bams/1183540922
writes that, according to an unpublished note of Selberg 3pi/2 can be replaced by 3.2. (this would give a larger improvement than
sqrt(22).
(The comment is repeated e.g. here:
A note on the weighted Hilbert’s inequality
XJ Li – Proceedings of the American Mathematical Society, 2005.
But I did not follow the history on this constant).
@Andrew and other programmers:
1) I am curious if s=sqrt(interval-length) in Andrews’s program for sieving the small primes is strictly best possible. Of course, there may be a reason (divisor < sqrt) of Eratosthenes sieve type.
2) Also: As you said that the min or max ist best for choosing the class a, (when the class of minimum frequency gives a tie) one could consider looking at classes that have very low (but maybe not minimum frequency), as long as the class is small.
(We have two principles, like frequency and class close to 0 mod p, but maybe we should weigh these principles slightly differently)
A small comment: now that we have the benchmarks, it is perhaps worth experimenting with different techniques than the current champion technique (greedy-greedy on shifted intervals with randomised breaking of ties); if a new method beats, say, the Zhang benchmark of 411,932 then it could be worth pushing further even if it doesn’t directly beat the current world record. (Scott mentioned a while back that he had some experiments with simulated annealing, I would be curious to see if that developed any further.)
@Christian: To your question (1), I have the impression that the method is not very sensitive to the choice of what you’ve called s, in the sense that once you’ve sieved out far enough, 0 appears to be the unique minimum-frequency residue class for a rather wide band around sqrt(interval-length).
@Christian: Thank you! It is strange that no more work has been done on this constant (or perhaps the problem is hard). At any rate, Selberg’s provisional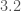 in place of
in place of  yields
yields 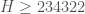 , while the conjectured value
, while the conjectured value  would give
would give 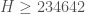 .
.
I think the record claimed in comment 14 is missing in the wiki.
Added, thanks! (though in principle the wiki is free to edit by anyone, after a registration which was implemented due to spam issues).
@charles: I concur with pedant (post 51) regarding (1). Regarding (2), I think the effect is likely to be very small. I have played around with a few weighting ideas to break ties (including incorporating Terry’s suggestion to also consider distance to the end points), but none seems to work as well as randomness. It’s not that any particular random sequence is likely to be better, it’s just that you can repeat them ad infinitum on the same interval (compared to the exponential number of random tie-breaking choices, the total number of intervals worth trying is very small).
I experimented with several different approaches today, but the thing that has proven most effective is just optimizing the code to allow more random attempts in less time. I also ran enough tests to convince myself that, as Wouter suggested, while picking the largest residue class in [0,p-1] to break ties is not always better than picking the smallest, it is better more often than not, so I changed the probability used in random tie breaking to favor the largest residue class about 80% of the time.
The net of all this is an admissable sequence of length 34429 with diameter 387,620.
http://math.mit.edu/~drew/admissable_34429_387620.txt
This recently released paper might be of use for considering optimising the sieving.
http://arxiv.org/abs/1306.1497
A note on bounded gaps between primes
Janos Pintz
As a refinement of the celebrated recent work of Yitang Zhang we show that any admissible k-tuple of integers contains at least two primes and almost primes in each component infinitely often if k is at least 60000. This implies that there are infinitely many gaps between consecutive primes of size at most 768534, consequently less than 770000.
For what it’s worth, I’ve plotted Engelsma’s values of the minimal diameter of an admissible
of an admissible  -tuple for
-tuple for  in a graph, just to get an idea of where this might be going. The blue line corresponds to Engelsma’s findings. The red line is
in a graph, just to get an idea of where this might be going. The blue line corresponds to Engelsma’s findings. The red line is 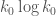 , which (at least in this range) is systematically dominated by the blue line. I’ve also plotted the difference (green line), which looks linear (with best fitting slope 0.9788) although Drew’s record suggests that instead it bends down slightly.
, which (at least in this range) is systematically dominated by the blue line. I’ve also plotted the difference (green line), which looks linear (with best fitting slope 0.9788) although Drew’s record suggests that instead it bends down slightly.
(Are there any finer heuristics known that would explain what this green line is?)
Extrapolating blindly to , one finds that $H(k_0)$ should be larger than
, one finds that $H(k_0)$ should be larger than 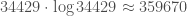 , and that it should be “near”
, and that it should be “near” 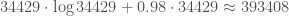 . So this suggests that 387620 is already in the right range.
. So this suggests that 387620 is already in the right range.
Again: for what these speculations are worth…
I have provisionally computed a value of from Pintz’s new preprint, but this should be viewed as unconfirmed at present. Also, there is room for further optimisation here.
from Pintz’s new preprint, but this should be viewed as unconfirmed at present. Also, there is room for further optimisation here.
@Wouter; unfortunately extrapolation is a bit dangerous: see Fig 2 of http://www.ccrwest.org/gordon/ants.pdf which compares the Schinzel sieve against the prime counting function (the horizontal axis here is roughly H, the vertical axis is roughly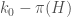 ).
).
Regarding extrapolations (comment 58): admits
admits
 integers, which might translate to:
integers, which might translate to: 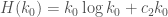 .
.
Based on the Gordon and Rodemich paper, and on our progress, my intuitive feeling is that so far the results are of type:
an interval of size
For comparison, the number of primes (as say in Zhang’s sieve) gives , i.e. has
, i.e. has  .
.
For fixed size reworking any bound/method into these constants
reworking any bound/method into these constants  could be some kind of measure.
could be some kind of measure.
(Asymptotically, that is for increasing or increasing interval size, this is of course not clear: Gordon and Rodemich describe heuristics which says that maybe $c_1$ increases very slowly (
or increasing interval size, this is of course not clear: Gordon and Rodemich describe heuristics which says that maybe $c_1$ increases very slowly ( . Also, to analyse the greedy-greedy and randomization asymptotically could be an interesting question…)
. Also, to analyse the greedy-greedy and randomization asymptotically could be an interesting question…)
addition, as some formule do not parse: is k_0 log k_0 + c_2 k_k…
is k_0 log k_0 + c_2 k_k…
…which might translate to
For comparison, the number of primes in an interval of size is about integrallogarithm of H, which is asymptotically
is about integrallogarithm of H, which is asymptotically
H/log H+ H/(log H)^2+ error term, i.e. has c_1=1.
I found an admissible set of cardinality 11123 and diameter 113520, see http://maths-people.anu.edu.au/~angeltveit/admissible_11123_113520.txt
If Terry is right that k_0 can be taken to be 11123 that yields an improvement of approximately a factor of 3.
How about if we try as v08ltu claims here: http://terrytao.wordpress.com/2013/06/03/the-prime-tuples-conjecture-sieve-theory-and-the-work-of-goldston-pintz-yildirim-motohashi-pintz-and-zhang/#comment-233178 ?
as v08ltu claims here: http://terrytao.wordpress.com/2013/06/03/the-prime-tuples-conjecture-sieve-theory-and-the-work-of-goldston-pintz-yildirim-motohashi-pintz-and-zhang/#comment-233178 ?
Unfortunately I won’t have time to write anything about simulated annealing for a few days; I’m heading off to a conference in a few hours and not taking a computer. Back before the greedy-greedy algorithm, when we were looking at Henley-Richards and shifted Henley-Richards sequences, I managed to (privately :-) beat some of the records using a simulated annealing process.
The idea was just to find a value of m that gave an admissible Henley-Richards sequence, and then reduce this a bit to start with an “almost admissible” sequence. Then I’d do a random walk, taking an element that fell into some minimally occupied residue class for some obstructed prime, and replacing it with something randomly chosen in the interval. However, before taking each step of the random walk, I’d check if it improved the “inadmissibility” of the sequence (which I took to be the sum of the sizes of the minimally occupied residue classes; so admissibility is the same as inadmissibility 0). If it did improve, I’d accept the step. If it didn’t improve, I’d accept it with some low probability.
(To really deserve the name simulated annealing you should let this probability decay to zero as you progress, but if you expect you’re unlikely to reach the global minimum, it’s not too important.)
Now, back then the bounds still had a lot of slack relative to current methods, so I have no idea if this is still worth pursuing. Someone should feel free to try some variation of this if they like; otherwise on Monday I’ll look again.
With k_0=10721 I found an admissible sequence of diameter 109314: http://maths-people.anu.edu.au/~angeltveit/admissible_10721_109314.txt
This can probably be improved quite easily, I didn’t search for very long. Some of the credit should go to Andrew Sutherland, I’m using a modified version of his c program from post 10.
Two new admissable sequences:
For k0=60000, with diameter 707,328
http://math.mit.edu/~drew/admissable_60000_707328.txt
For k0=10721 with diameter 108,990
http://math.mit.edu/~drew/admissable_10721_108990.txt
I also have sequence for k0=11018 and k0=11123 that I will post shortly.
For k0=11123 with diameter 113462:
http://math.mit.edu/~drew/admissable_11123_113462.txt
For k0=11018 with diameter 112302:
http://math.mit.edu/~drew/admissable_11018_112302.txt
Slight improvement to the last sequence above for k0=11018 now with diameter 112,272:
http://math.mit.edu/~drew/admissable_11018_112272.txt
I notice that it looks like k0 is now down to 10719. So far the best I can do for this is to just trim the last two entries off the diameter 108,990 sequence of length 10719. This yields an admissable sequence of diameter 108978 that I have for reference posted here:
http://math.mit.edu/~drew/admissable_10719_108978.txt
I also have some minor improvements to a few of the sequences posted for larger k0 values above, but I won’t bother posting them unless someone asks for them.
In terms of some alternative optimization algorithms besides the randomized greedy algorithm used to obtain all the sequences I posted above, I thought I’d mention a couple of ideas I have been playing with. They are all likely to be much more time-consuming than the randomized greedy approach, but as k0 gets smaller, this is less of an issue.
1) Yesterday I actually tried an approach that builds an admissable sequence within a given interval by adding integers one-by-one in a way that preserves admissability, rather than sieving integers out of the interval. The idea is to start with a small initial set of integers, say of size sqrt(k0) (currently I do this by sieving out 0 mod small primes and picking a dense subset) and to then assign a weight to every other integer in the interval based on how many *new* residue classes you would hit if you added the integer to the set (inversely weighted by the size of the prime). Pick the integer with the least weight, recompute all the weights, and repeat.
This proved to be very slow and didn’t produce inspiring results. But that doesn’t mean the idea can’t be made to work.
2) As a variation on the randomized greedy approach, today I want to look at implementing an intelligent look-ahead strategy when picking the residue class to sieve (e.g. compute the number of integers lost for various choices of residue classes for each of the next n primes, for some small n (maybe 3 or 4).
I plan to give this a try today.
3) Another approach would be to try to build large narrow admissable sets from smaller ones. Suppose someone gives you an min-diameter admissable set of size k0/2, can you use this to get a small diameter admissable set of size k0?
4) Regarding Scott’s comments on simulated annealing (post 63), I have had good results with simmulated annealing on other number-theoretic optimization problems (see http://ants9.org/slides/poster_caday.pdf, for example). I’m not sure how well this one fits a simmulated annealing model, but a simple version would be to modify the randomized greedy approach to initially be more flexible about its random choices (don’t always choose a residue class that kills a minimal number of integers), then gradually become less flexible as the temperature parameter goes down.
5) Finally, it might also be worth thinking about a branch-and-bound approach, but I haven’t really thought this through to any degree. We might need k0 to be quite a bit smaller before this becomes practical.
Interestingly, for k0=10719 (and smaller k0 in general, I suspect) one does better with an interval that does not span 0. Using the interval [7858,116492] I get an admissable sequence of diameter 108634.
http://math.mit.edu/~drew/admissable_10719_108634.txt
layment question: how hard is it to pinpoint a number?
Here’s a thing one can try to enhance a given admissible set S. One looks for a reasonably nice admissible set T in the same region, takes the union S U T, and repeatedly applies the greedy-greedy algorithm starting from that union (with fully randomized tie breaks, i.e. not only min vs. max). As soon as the result is more narrow than T, replace T by that result and continue. In doing so one can hope to benefit from the “right” sieving choices that were made in the construction of S (by testing them against T), and to improve the bad ones.
All of this is a bit vague of course… In any case, I applied this to Drew’s record #69, peeling off a modest 2.
108632.txt
Probably the gain will always be very small, but maybe this trick can be improved?
I found a slightly better sequence for k0=10719 with diameter 108600.
http://math.mit.edu/~drew/admissable_10719_108600.txt
Wouter, perhaps you can try your trick again with this one?
Ok, I just did. Now the gain is a little more (but still not a lot):
108570.txt
Ok, so by running a new version of my algorithm (which also looks for post-optimizations around the end points) I was able to improve the diameter of your sequence to 108556
http://math.mit.edu/~drew/admissable_10719_108556.txt
Can you further improve this sequence?
Hi, Unfortunately, I found an error in Pintz, and it checked out with what I got from a Ben Green post (though neither has confirmed). See Terry Tao’s blog comments. If this is indeed the case, the new constraint is $1/4 \le 207\omega + 43\delta$. Via optimization, I get $\delta = 1/942$ allows $k_0=25111$ the latter best possible. Sorry…
http://terrytao.wordpress.com/2013/06/03/the-prime-tuples-conjecture-sieve-theory-and-the-work-of-goldston-pintz-yildirim-motohashi-pintz-and-zhang/#comment-233310
For benchmarking purposes let me just note that Schinzel sieve didn’t go under 113000 and Erasthothenes, while sligthly better, basically remained at the same level (that is for k=11,018).
So far pure greedy works best for me although it still lacks behind current records.
I’ve hacked together Andrew’s idea 2 but Python is painfully slow and I’m still waiting for the results.
@Drew: No, at least not immediately. I’ll let it run for some longer time.
But it’s not unlikely that the point of saturation has already been reached here. Note that, when compared to your 108600 sequence, the whole lot has been shifted to the right a bit. I guess that’s what this trick is capable of doing: once you are very near a “hotspot”, it can push the sequence towards it. Once you’re on it, it won’t help any more.
Anyway, according to v08ltu’s post #75, we’re back to !
!
Just found a solution based on the two solutions in #74 and #72:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissable_10719_108550.txt
I want to leave a quick remark about something that as far as I’ve been able to tell doesn’t help, in case it gives someone else a better idea. One might imagine that (after the initial sieve of primes less than the square root of the interval length) there’s a better order in which to sieve than simply in increasing order of the remaining primes. [Well, perhaps that’s unimaginable to an analytic number theorist; I am not one!]
For instance, rather than sieving out one of the minimally-occupied residue classes for the smallest currently-obstructed prime, I wondered whether it might be better to sieve a minimally-occupied residue class at a prime p for which the ratio (multiplicity of the least-obstructed residue class)/(average multiplicity of a residue class) was minimized (or in other words for which p*(multiplicity of least-occupied residue classes) was minimized). However, in my experiments it looks to me like this does a little bit worse than just sieving the primes in order.
For finding the solution in #78, I have built a meta-heuristic algorithm. The basic idea is to take an existing solution as an incumbent solution, and then using elements in other solutions as reference elements for further improving the incumbent solution. But I found some some heuristics (e.g., adding one, adding two and removing one) do not work. So the final version an GreedyALL version: i.e., first adding all external elements, and remove some of them in a greedy way by minimizing the conflicting cost to 0.
I found this problem is kindly similar to find an independent set in graph coloring, so I added some basic tricks to reduce the computational time of local operations.
BTW: In #78, the incumbent solution is from #74, and the reference elements are from #72.
I will post the code (in JAVA) after clearing the code.
Is the following true?
————————————————–
Primes are uniformly distributed
Let p, r, n are positive integers with p>1.
U(p, r, n) denotes the number of primes less than n that are equal to r (mod p).
For any prime p and pair of integers r1, r2 between 1 and p-1, we have:
The ratio U(p,r1,n) / U(p,r2,n) has limit 1 as n goes to infinity.
Here’s a sequence to get the ball rolling with k0=25,111, with diameter 275,424. I’m sure it can be improved:
http://math.mit.edu/~drew/admissable_25111_275424.txt
@xfxie: I’ll be interested to see the details. It looks like both you and Wouter could benefit from having a number of “good” sequences that you can then try to improve. I’ll try to find a couple of different ones.
I was able to further improve the sequence from #78 for k0=10719, bringing the diameter down to 108,540. This k0 may no longer be relevant, but I thought I would post it as a matter of interest. We seem to be able to profitably iterate different optimization techniques.
http://math.mit.edu/~drew/admissable_10719_108540.txt
@pedant: Regarding post 79, I also tried varying the order of the primes, but like you, I have so far not found it to be beneficial.
Here is another sequence for k0=25111 that’s in different area and slightly better, with diameter 275,418.
http://math.mit.edu/~drew/admissable_25111_275418.txt
Another one :
For any number e > 1, there exists a number N, such that for any M > N, there is at least one prime between M and e x M.
Oops, I realize I should have posted this sequence, which is essentially the same but slightly narrower:
http://math.mit.edu/~drew/admissable_25111_275404.txt
Using the merging trick, sequence #87 can be brought down to 275,292. Can your endpoint optimizations narrow this further?
25111_275292.txt
(@ZTOA, check Bertrand’s postulate)
@Wouter: I think I’ve got it down to 275266 using your merging trick.
oh, excellent! (and even to 275264 I noticed)
Just got a solution 275388 based on #87 ( the reference elements are from another solution generated by Andrew’s software).
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_25111_275388.txt
I just checked #88 (using Andrew’s software). It is admissible, but k0=25013. Maybe I am wrong, because I have to pre-process the data since the format is different.
Starting from your sequence, my computer then found an admissible sequence of diameter 275126. Probably that’s not the end of it.
@andrew: I just saw #82. Yes, the current realization assumes the incumbent state is a good solution, but the reference elements can come from a “plain” solution (or multiple of them).
@xfxie, our messages crossed. By “starting from your sequence” I meant the one of pedant.
It would be interesting if you could apply your machinery to the above sequences. I think they consist of the right number of elements, so I would guess that something goes wrong with pre-processing the data. But I’ll double-check it tomorrow (I’ll call it a night here). If you wish I can then give them in Andrew’s format.
@Wonter: I just checked 25111_275248.txt on the dropbox, it is correct. Sorry for the mistake since I pre-processed the data by hand.
@Wouter: That’s great! (but I think the link to your 275126 sequence is broken?) I think I’ve got my code set now so that it can run without my interference (i.e. it can re-start itself if it gets stuck), so I’ll let it run through the night. I’m down to 275214 now, myself; same folder as in #89.
Let’s hope there’s no horrible bug whereby the program puts all sorts of incorrect nonsense in the dropbox folder while I’m asleep. (:
@Wonter: Based on your comment, I run the software on your solution 25111_275214.txt, and obtained 275208.
The solution 275208 is located at:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_25111_275208.txt
BTW: Maybe 25111_275214.txt is from #97 @pedant, I just downloaded from the dropbox.
@xfxie: Yes, the dropbox here is mine (and updates automatically if the program finds something new).
@pedant: thanks for noticing. Here’s a (hopefully) working link: 275126.
@Wouter: thanks! we must be doing something a bit different from each other, because my admissible sequences were drifting somewhat (the one of length 275266 started at -118532, and by the time I’d gotten the length down to 275166 the starting point had drifted up to -116542), while your 275126 was very close to my 275266.
I’ve re-started the program beginning with your 275126 and have it down to 275090 now. Hopefully we can get mileage from taking turns like this!
Since it seems that we’re back to k0 = 34429 for the time being (see here), I’ve switched over to running on that, starting on Drew’s 387620 in comment #56. There’s a 387534 in the Dropbox now (link at comment #100).
I think one can take k0=26024 from the corrections to the improvements in the first half of Pintz (assuming the rest of it is Ok), and the noted expression (30) for kappa. I heard some chatter of improving kappa in any event.
@v08ltu: Thanks for keeping us up to date on k0 developments.
I’ve just kicked off a scan for narrow admissable sequences of length k0=26024. I should have some sequences to post in a few hours.
Here’s a starting point for k0=26024
http://math.mit.edu/~drew/admissable_26024_286224.txt
I’ll post a few more as I find them.
Some new records:
http://math.mit.edu/~drew/admissable_25111_274894.txt
http://math.mit.edu/~drew/admissable_26024_285810.txt
http://math.mit.edu/~drew/admissable_34429_387006.txt
These were all generated with a modified version of the randomized greedy algorithm that I think effectively incorporates a version of Wouter’s optimization. It generates multiple sequences in the same interval and then plays them off against each other). I also added a “contraction” step: whenever an admissable sequence is generated, it checks to see if either endpoint can be replaced by an interior point (and if so, does this). Previously I was only doing this check at the end, but interleaving contractions seems to work better.
@pendant, @xfxie, @wouter: I’ll be curious to see how easy it is for you to further optimize these (probably 26024 is the one to focus on, since this appears to be the current k0, and it is also the sequence that I expect is the least optimized). We all seem to be doing something slightly different, so it will be interesting to see if we can continue to profitably interleave our optimizations.
Found a solution 286216 for k0=26024, based on #106:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_286216.txt
@Drew: OK, I’m at work on the 26024 record. Found a 285798 very quickly, and am now at 285758; see the dropbox (post #100), which will be updated automatically as the code runs further.
@Drew,xfxie,Wouter: Conversely, I’d be interested to know how easily your algorithms can improve on the 34429 / 387380 that’s in the dropbox. It started from Drew’s 387620, was pared down to 387380 in a rapid series of improvements, and then was stuck there for most of the night.
It looks like each of the two parts of the deduction leading to have been confirmed, so we’re going to declare this value as “safe to use”. Sorry for all the confusion over the past 24 hours!
have been confirmed, so we’re going to declare this value as “safe to use”. Sorry for all the confusion over the past 24 hours!
@Terry: that’s good news, thanks!
Two new records:
http://math.mit.edu/~drew/admissable_34429_386814.txt
http://math.mit.edu/~drew/admissable_26024_285498.txt
I guess the later gives the current best bound on H of 285,530, using k0=26024 (but I’m sure this bound will be improved in short order).
For the benefit of those experimenting with various optimizations that work from a good starting point, here is a sequence for 26024 that is not as good as the record above, but uses a substantally different interval and is close enough to the current record that some optimization might push it over the top.
http://math.mit.edu/~drew/admissable_26024_285660.txt
@pedant: Starting from your 387380 sequence for k0=34429 I was able to work down to 387176, but this doesn’t really mean anything other than that there is a better sequence in roughly the same area.
The algorithm I am using now doesn’t really depend that much on the starting sequence (by default it just generates one in a given interval), it’s really just a matter of the interval, since after enough iterations its capable of completely changing the sequence. The sequences for 26024 listed above were both obtained starting with not very good sequences: the total diameter improvement from start to finish was well over 1000. In any case, here is the sequence I wound up with:
http://math.mit.edu/~drew/admissable_34429_387176.txt
I’m starting to converge to on an algorithm that I’m pretty happy with (at least until I think of something better!). If I have time this afternoon I’ll post the details of exactly what I am doing. I’ll eventually post C source code, but I want to wait until things stabilize before I take the time to clean it up and make it presentable.
Oops, I realize I actually had a better sequence for k0=34429 sitting in my directory:
http://math.mit.edu/~drew/admissable_34429_386750.txt
That’s it for k0=34429.
I am getting a little bit lost. I think it’s more important to concentrate on figuring out the best algorithm for creating narrow admissible sets and leave the hand fine-tuning for minute improvements when the other group has confirmed the best $k_0$ possible.
I’ve created table of (some of the) narrow admissible sequences here: https://docs.google.com/spreadsheet/ccc?key=0Ao3urQ79oleSdEZhRS00X1FLQjM3UlJTZFRqd19ySGc&usp=sharing (please ask me for editing rights to help me add more!). So far it seems that Sutherland leads in density with 10719_108540.
Which leads me to the question: “Is there any better measure than density?” I’ve noticed it’s easier to produce shorter sequences of higher density so maybe we should discount for that. It could be later used as a heuristic in search for “the optimal sequence”.
On another note, I’ve played with Fourier analysis a bit this morning. It seems that generally the diameter of an admissible sequence H grows as 10*length(H). However if one computes the first difference of H and feeds it to FFT the results can be pretty interesting. See https://github.com/vit-tucek/admissible_sets for examples on small sizes.
@Vít #112: I think the point here is just to start to understand the fine-tuning process; the interest does not lie in whatever records happen to be found during that experimentation. Indeed it may well be that the best way to find very good narrow admissible sets in practice will be to produce good narrow admissible sets in some structural way, and then to improve them by some perturbation method. In the absence of any new good structural ideas for creating narrow admissible sets from scratch, we’re thinking about the perturbation step, so that we’re ready to put that process to work when new values of $k_0$ are obtained from improvements to $\varpi$.
I just put the code online:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissibleV1.0.zip
From my practices, it really needs some good luck to find better solutions using the current realization.
But it might be good starting point for realizing various meta-heuristics that might by more efficient.
BTW: the code is in JAVA.
@Vit: I agree 100% that this is all about developing the best algorithm. Having said that, the back and forth between Castryck, pedant, xfxie and myself over the past 24 hours has been extremely helpful in this regard — the realization that we could consistently improve each other’s sequences and being able to go and compare the specific details in the differences has led to substantially better algorithms. Let me take a shot at describing the algorithm I am now using — I’m sure the others can chime in with their own comments and/or additions.
Let me first give the broad strokes of the algorithm, I’ll fill in details of each step below. The essential components of the algorithm are a randomized version of the “greedy-greedy” algorithm that breaks ties at random, and the merging process suggested by Castryck in post 71.
Given k0, generate a dense admissable sequence of length k0 as follows:
1) Determine an easy target diameter D.
2) Determine a good interval I of width D.
3) Use the greedy algorithm to construct an admissable sequence H1 in I. Contract H1 (as explained below).
4) Repeat the following steps indefinitely:
(a) Use the randomized-greedy algorithm to construct an admissable sequence H2 in the interval [b0-delta,b1+delta], where
[b0,b1] is the smallest interval containing H1 and delta, is a small fraction (I use delta = 0.0025). Contract H2.
(b) if diam(H2) < diam(H1), replace H1 with H2 and go back to (a).
(c) Let S = H1 union H2. By construction, S will avoid odd numbers and 0 mod p for p sqrt(D) up to k0, breaking ties randomly. This will yield a new admissable sequence H3. Contract H3.
(d) If diam(H3) < diam(H2), replace H2 by H3, otherwise repeat b up to some max number of retries (I use 5-10). If you cannot reduce the diameter of H2, go back to step a. If you can, go to step b.
Now for some more details:
1) Determining the target diameter is easy to do empirically, e.g. run the greedy algorithm on increasingly large intervals centered about the origin until it succeeds. To first order, the diameter should be about k0*log(k0), see https://perswww.kuleuven.be/~u0040935/k0graph.png
2) To determine a good interval, I run the deterministic greedy algorithm (breaking ties upward, as suggested by Castryck) on the sequence of intervals [b0,b0+D] for b0 varying from -1.5*D up to 0.5*D, jumping by, say 0.001*D. This will generally suggest several good areas to look for dense admissable sequences.
3) To "contract" an admissable sequence means to check whether there is any interior point that can replace an end point, or whether there is a point past an end point that could replace the other end point and yield a narrower sequence. Most sequences produced by the greedy algorithm tend to be non-contractable, but it is still worth checking because many are. It's not necessary to contract at every stage (it takes time to check, so there is a cost), but I wrote it that way for simplicity.
4a) The parameter delta is critical. This "fudge factor" gives the algorithm enough room to easily construct H2, and moreover, it actually allows it to gradually move the target interval around, which is a good thing. It also helps to avoid the "saturation" that Castryck mentioned.
4c) Note that this is guaranteed to succeed, since S is already known to contain an admissable sequence (in fact two).
4d) The number of retries to allow is a performance trade-off. Too few and you might give up to early, too many and you waste time beating your head against the wall.
Now the algorithm above may sound somewhat involved, but it is actually quite easy to implement using the "greedy-greedy" code I posted earlier, it is very fast, and it is easy to parallelize (run as many simultaneous copies as you want). There are a few performance optimizations worth making, but for the sake of space I won't comment on them here. When I have time I will clean up my code and post a C implementation of the algorithm above.
As evidence of the efficacy of the algorithm, I ran it with the initial sequence H1 set to the diamter 108540 sequence for k0=107190 that you noted as the best in your table (by the way, the density should asympotically be about log(k0), so you really should weight by this when comparing different k0's). It then quickly found a diameter 108514 sequence in roughly the same area that I never could have found with the original deterministic greedy algorithm, and that would have taken ages to find with a blind randomized greedy algorithm. Here is the sequence:
http://math.mit.edu/~drew/admissable_10719_108514.txt
I see that step 4c got garbled when I cut and paste, it should read:
(c) Let S = H1 union H2. By construction, S will avoid odd numbers and 0 mod p for p up to sqrt(D). Now greedily sieve S of residue classes for each prime p > sqrt(D) up to k0, breaking ties randomly. This will yield a new admissable sequence H3. Contract H3.
To “greedily sieve” means pick a residue class that hits a minimal number of elements of S. When there is more than one choice, pick one at random (I currently do this uniformly, but I could argue for weighting it upward).
A modest improvement to the current record for k0=26024, produced by the algorithm described in #116. Diameter 285,458.
http://math.mit.edu/~drew/admissable_26024_285458.txt
Drew, do you mean [b0-delta*D,b1+delta*D] in 4(a)?
What I’ve been doing is very close to what Drew is doing, so let me just note the differences. I have no particular reason to think that these differences are improvements, but diversity for its own sake may help.
* I haven’t been doing the contraction step (but probably I should!).
* My implementation of greedy-randomized greedy is slightly different. After sieving out 0 mod p for p up to sqrt(D), I continue to sieve out the residue class 0 mod p for all subsequent primes (up to k_0, of course) for which 0 is a minimally-occupied residue class. I have no evidence that this is better or worse than just sieving up to sqrt(D). (To be honest for a while I’d forgotten that I was doing this — it’s an ‘option’ that I thought I had turned off — but I when I noticed I was still doing it, I left it in in the name of diversity.) The randomized greedy step then proceeds in the same way.
* Assuming that [b0-delta*D,b1+delta*D] was meant in 4(a) of Drew’s post, my delta is somewhat smaller than Drew’s, roughly 0.0014. As a result, the admissible set H2 sometimes has fewer than k_0 elements in it, so I have to repeat step 4(a) until I hit one that has at least k_0 elements in it.
* At the end of step 4(c), in lieu of the contraction step, I replace H3 (which may have more than k_0 elements in it) with the narrowest subset of H3 of size k_0, breaking ties randomly in case there are several equally narrow subsets. (This means that in the first pass through step 4(c), the set H2 comes from 4(a) and may have more than k_0 elements, but in subsequent passes it has exactly k_0 elements.)
* In step (d), I’ve been allowing more re-tries (100).
Oops, also meant to say, I’ve been letting delta vary in a small band (from 0.0013 to 0.0015) just to introduce another source of variation in the process.
@Drew, thanks a lot for this description, and for the 285458 sequence: I wouldn’t have guessed that there would be so much room for improvement!
I never wrote a fully automatized implementation of the algorithm; I just have a number of pieces in Magma (e.g. deterministic greedy-greedy, and something which resembles 4(a)(c)(d) in Drew’s above description) that I combined by hand. My implementations are too slow to keep up with the ones of Drew and pedant, anyway.
Some differences (none of which I believe are improvements):
* My delta was usually somewhat smaller (less than 0.001), and in fact my interval was not always chosen symmetrically around [b0,b1]. Sometimes I tried to pull things to the right or to the left by giving more freedom on one side. I don’t know if this helped (sometimes this resulted in a nice sequence, but that might have been a coincidence).
* I experimented a bit with given higher probabilty to certain residue classes. In fact, here the story is the same as in pedant’s case: I put it in at some point, and then forgot about it. I don’t have enough statistics to tell whether it helps or not, but my impression is that it doesn’t really matter.
@pedant: Yes, I meant [b0-delta*D,b1+delta*D] in 4(a), thanks. And even with my larger delta it happen that fewer than k0 elements are left after sieiving, in which case just retry. And whenever there are more than k0, I always pick the narrowest k0, as in the original greedy-greedy implementation. It may still happen that this admissable sequence is than contractable (the larger the input interval is relative to the diameter of the result, the more likely this is to be the case, as S gets smaller, H3 is less likely to be contractable).
Another interesting thing to look at is the difference between the size of S and k0. In step 4(a) with k0=20624 this will typically be around 500 or 1000, and then gradually dwindle down to around 20 or 30 as step 4(c) and 4(d) repeat. I originally used the parameter T=|S|-k0 as the guideline for when to restart in 4(a) (wait until T is below some small fraction of k0, say 0.1 percent), but this occasionally meant the algorithm would get stuck, so I put in the max retries parameter.
In simulated annealing terms, you can view T as the temperature of the system – it represents the amount of freedom the algorithm has in choosing an admissable subset of S. One way to describe this algorithm would be as iterated simulated-annealing with a greedy backbone (we are basically being greedy, the only randomness is in tie-breaking, but this already allows a lot of freedom).
@vit I love your FFT images, very cool! I’d be curious to see the same for these two sequences, also for k0=26024, but in significantly different intervals.
http://math.mit.edu/~drew/admissable_26024_285660.txt
http://math.mit.edu/~drew/admissable_26024_285774.txt
I’ve been using the number of obstructed primes for S as my “temperature” parameter, probably not so different in practice from what you’re doing. Actually here’s maybe a better way to go about it that occurs to me now (haven’t implemented this yet): keep track of the amount of information in the random choices being made, i.e. the quantity b := the sum over obstructed primes p for S of log(# of minimally occupied residue classes). If b gets stuck above a certain threshhold, allow yourself a certain maximum number of retries; when b falls below that threshold, just iterate (in a random order?) through all exp(b) possibilities until you either exhaust the possibilities or find a winning choice.
Comment from a newbie ignoramus – I hope not too irrelevant:
It seems that there is a lot of effort going into optimising the best interval for a given k0 in the current range, but I’m not seeing any talk about optimising the efficiency of algorithms to identify the provably best interval for a given (necessarily smaller) k0. In view of the rapidity with which improvements in omega and thus in k0 may plausibly occur over the next weeks or months, my impression is that there is a case for putting in a fair amount of work now into improving the efficiency of algorithms to derive the provably best interval for a given k0, so that the implications of improvements in omega can be quantified at once as soon as omega gets big enough. (All, of course, under the presumptions that we are already close to getting the best k0 for a given omega and that we will not see big departures from Zhang-esque overall proof structures.) Is such work happening, and, am I right that there is a case for it? If yes or no respectively, please elaborate :-)
@Andrew: I’ve uploaded the images to github. The source there also contains the code to produce them. (On windows I can recommend downloading winpython that gives you all the packages you need and Spyder IDE which is imho quite good. The plot command then pops up new “figure” window where you can zoom/pan/change scale to logarithmic etc.)
I’ve been thinking about better graphical representation of admissible sequences but I haven’t come up with anything so far. All the information is contained in the sifted residue classes… If only there was some sort of number theoretical version of FFT… :)
Thanks a lot for explaining your algorithms guys. I am unfortunately too busy to come up with some more code of my own.
@Aubrey: You have a fair point in my opinion. Although complexity of this problem is quite high. On the other hand, the best results so far (if I am not mistaken) regarding optimal sets set the record size around 1000 and are from around 2000 so there maybe some room for improvement. I was actually thinking about pinging the authors that have written on the topic to see whether they are still interested. But I am too busy at the moment.
@Vit: I’m not entirely sure what to make of the FFT plots, but they are definitely fun to look at, thanks.
@Aubrey: During the past week we haven’t had a single value of k0 that was stable for more than about 48 hours. But certainly once we are confident k0 has been optimized to the extent possible, lower bounds on H for that k0 become interesting. In fact for k0=34,429, which briefly looked stable, the lower bound H >= 234,322 was established (see the records page). This is almost certainly much lower than the true value, and far below the best upper bound H <= 386,750 we have (see post 112). I'm, sure someone will crank through the numbers for k0=26,024 if it stands up for more than a few days. In terms of getting tight bounds on H, as Vit indicated, this is probably hopeless for k0=26,024, but if k0 gets small enough it might become feasible.
Some benchmarks for k0=26,064:
Zhang (m=655): 303,558
Hensley-Richards (m=723): 297,454
Asymmetric Hensley-Richards (m=723, i=13542) 297,076
The current best using the algorithm in #114 is 285,456.
http://math.mit.edu/~drew/admissable_26024_285456.txt
After letting the algorithm run over night, the diameter is down to 285,436.
http://math.mit.edu/~drew/admissible_26024_285436.txt
Just injected some new components into the algorithm for tackling with the problem structure, and the performance become better.
The solution 285446 is built on #128 :
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285446.txt
The solution 285432 is built on #129:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285432.txt
The basic trick is to build a core set and allow plateau moves:
Just generated more solutions:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285420.txt
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285418.txt
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285406.txt
@xfxie: excellent. Here’s a similar but slightly better sequence, can you improve this one?
http://math.mit.edu/~drew/admissible_26024_285430.txt
Sorry, here is a better one to work from:
http://math.mit.edu/~drew/admissible_26024_285378.txt
@andrew: Just got #133 as well, and then the algorithm stuck in the plateau for many rounds. The algorithm might need some perturbation operations.
Maybe pedent’s algorithm can help escaping from the local minimum.
Just a new one:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285328.txt
Another one (285324):
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285324.txt
@xfxie: I agree, some perturbations definitely appear to help, I’m now making progress again, down to
http://math.mit.edu/~drew/admissible_26024_285326.txt
Or even 285318:
http://math.mit.edu/~drew/admissible_26024_285318.txt
285314, seems there are so many plateau levels:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285314.txt
Stuck at 285304:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285304.txt
Still making progress…
http://math.mit.edu/~drew/admissible_26024_285288.txt
@xfxie 131: I agree on the plateau moves. In terms of the description in #116, I changed the algorithm to replace H2 with H1 in 4(b) even when the diameters are equal. This happens quite often, and usually H2 and H1 will still have the same endpoints, but *different* interior points. After letting several threads run for a few minutes, I found that they were all using different H1’s of the same diameter in the same interval. This gives the algorithm more freedom to find new solutions.
I’m now down to 285,278:
http://math.mit.edu/~drew/admissible_26024_285278.txt
I don’t have time to implement this right now as I have plans for the rest of the morning, but here’s a remark about how one might try to make these improvements in a systematic way, rather than using randomness. Hopefully one of the others will be able to make this go.
If S is an admissible set, I’ll say that c an unobstructed residue class mod p if S contains no elements that are congruence to c (mod p); otherwise say that c is obstructed. I’ll say that c is a minimally obstructed residue class mod p if c is obstructed, and the number of elements in S that are congruent to c (mod p) is minimal among obstructed classes.
Start from an admissible set S, let I be the interval [Min(S)..Max(S)], and look for a pair of primes (p,q) with the following properties.
— there exists a minimally obstructed class c for p, and a minimally obstructed class d for q, such that T1 := { x in S : (x mod p) eq c } and T2 := {(x in S : (x mod q) eq d } have nontrivial intersection. Let the sizes these sets be C, D respectively.
— there exist unobstructed classes c’ for p and d’ for q such that there are at least C elements in T3 := {x in I : (x mod p) eq c’ } such that adjoining them to S would only obstruct p, and at least D elements in T4 := { x in I: (x mod p) eq d’ } such that adjoining them to S would only obstruct q.
Then one can alter S by deleting T1, T2, and either endpoint of S, and adjoining T3, T4 to obtain a narrower admissible set with the same number of elements.
For instance, one can get from S := Drew’s 285458 (post #118) to his 285456 (post #128) in this manner. Take p = 2543 and q = 3683. The class c = 716 is minimally obstructed for 2543, and 1998 is minimally obstructed for 3863; we have T1 = {-34886,-50144,102436} and T2 = {102436}, with nontrivial intersection. We’re forced to take c’ = 2270 (it’s the only unobstructed prime for p in S), but fortunately T3 = {-70036,-53758,92744} has size 3. There are multiple choices choices for T4; the one he happens to use is d’ = 3829, T4 = {38596}.
(This does not produce exactly the set of diameter 285456 that Drew has, as there are also various sideways moves, e.g. 110756 is removed and 29258 is added, affecting only which classes mod 4513 are obstructed. It’s conceivable to me that this has some of the elements of what xfxie means by moving around on a plateau? That terminology is too vague to know for sure just from the choice of words.)
One can of course imagine improvements where you allow yourself to add classes that are just beyond one endpoint of I so long as you’re not going so far as the distance from the other endpoint of I to the first number in the interior.
@pedant: I can implement this as a generalization of the contract step in #116. Another optimization I have added is to try shiting the set by successively removing points from one end and adding them to the other (in a way that preserves admissibility). One occasionally gets a reduction in diameter this way.
I’ve started a new wiki page at
http://michaelnielsen.org/polymath1/index.php?title=Finding_narrow_admissible_tuples
to describe all the known sieves for finding good tuples, as well as lower bounds, and also a more systematic table for the benchmarks. I didn’t describe the most recent sieves (greedy-greedy and beyond); if someone who is more familiar with the more recent methods could give some descriptions there (and maybe also links to code etc.) that would be great!
@Tao,Sutherland: Is 26,064 in table a typo? (expecting 26,024)
Oops, that was a typo and has been corrected (on the wiki at least), thanks. (I’m assuming it was a typo in #128 as well.)
@Tao: I can take a shot at this, I was planning to latex up a more coherent version of post #116 in any case, but it may be tomorrow before I can get to it. And yes 26,064 in #128 was a typo, it should have been 26,024.
I was also going to suggest recording the best upper bounds we have for some of the older/provisional bounds of k0 in the records table (some of these didn’t make it in during the confusion when k0 was unstable or were posted after they were obsolete). If k0 happens to change in the future these would be good to have (e.g. the best upper bound 386,750 for the previous k0=34,429 (post #112) isn’t listed, but this could become relevant if for some reason k0=26,024 came into question). I can put these in to the table if you want, just let me know.
Here are some benchmark lower bounds for , to be included in the new wiki page. (The benchmark section in the old wiki page should be replaced by a link to the new wiki page. Please note that I am not familiar with editing wiki pages.) The new data:
, to be included in the new wiki page. (The benchmark section in the old wiki page should be replaced by a link to the new wiki page. Please note that I am not familiar with editing wiki pages.) The new data:
 by first MV
by first MV
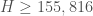 by Brun-Titchmarsh
by Brun-Titchmarsh
 by second MV
by second MV
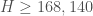 by MV with
by MV with 
 by MV with
by MV with 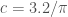
 by MV with
by MV with 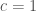
I should have used . Let me update my data quickly.
. Let me update my data quickly.
I mean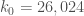 .
.
Here are some benchmark lower bounds for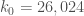 , to be included in the new wiki page. (The benchmark section in the old wiki page should be replaced by a link to the new wiki page. Please note that I am not familiar with editing wiki pages.) The new data:
, to be included in the new wiki page. (The benchmark section in the old wiki page should be replaced by a link to the new wiki page. Please note that I am not familiar with editing wiki pages.) The new data:
 by first MV
by first MV
 by Brun-Titchmarsh
by Brun-Titchmarsh
 by second MV
by second MV
 by MV with
by MV with 
 by MV with
by MV with 
 by MV with
by MV with 
Just post the code V1.1 online:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissibleV1.1.zip
@pedant #143: I implemented the optimization you suggested. So far I can’t report any improvement on the current record (see below), but I have verified it works on your example and it does periodically improve intermediate sequences. It’s too time consuming to apply routinely after sieving, so I only apply it at the point where the algorithm is ready to give up and generate a new H2.
Two points I noticed during the implementation:
1) It can actually happen that T3 is smaller than T1, completely independent of whether T1 intersects any T2 non-trivially, in which case we can immediately replace T1 with T3. The algorithm checks for this first before looking for intersecting T1’s and T2’s.
2) One needs to be careful with the definition of T3. The computationally simplest thing (and what I do) is to require that each element of T3 would yield an admissible sequence if it were individually added and T1 were removed. But it is possible that collectively the elements of T3 might create an obstruction at another prime. So it is important to check after the fact that the result is still admissible (and in practice it almost always is).
The current record (found by a modification of the algorithm in #116 to allow “lateral moves”, i.e. replacing H1 with an H2 of equal diameter, which is how I interpreted pedant’s comment about moving around on a plateau) is now 285,272
http://math.mit.edu/~/drew/admissible_26024_285272.txt
There were no specific perturbations or local optimizations used to find this, it was just random-greedy sieving with iterated merging, so maybe someone can tweak this sequence further.
Sorry, when I mentioned plateau’s above I was referring to xfxie’s comment.
[There’s a typo in Drew’s link in #154. The corrected link is http://math.mit.edu/~drew/admissible_26024_285272.txt.%5D
Ha, wordpress didn’t like that right-bracket. Trying again: http://math.mit.edu/~drew/admissible_26024_285272.txt
@Gergely: Thanks for the benchmark data (and thanks to whoever added them already to the wiki)! I’ll remove the old benchmark section as it is obsolete.
@Andrew: I think it would be good to expand the benchmark table in whatever way you see fit, including current world records for each . (Another possibility is to record the optimised Schinzel sieve data.)
. (Another possibility is to record the optimised Schinzel sieve data.)
@pedant: sorry about the typo, thanks for the fix. They obviously shouldn’t let me near a keyboard (see, e.g., #156).
But I can report some success! After making a random lateral transition from one diameter 285272 sequence to another, the algorithm hit a sequence that could be successfully “adjusted” using #143. This only reduced the diameter to 285270, but the random-greedy-iterated-merging (really should give this thing a name) quickly brought this down to 285,248.
http://math.mit.edu/~drew/admissible_26024_285248.txt
@Terence: I’m working on the Schnizel benchmark now. I can’t get my hands on his original paper at the moment, but there is a nice recap in the Gordon-Rodemich ANTS paper pointed out by Christian.
Just obtained 285272 based on the solution in #154 using #153:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285270.txt
#161 should 285270
285246 based on solution in #160 using #153:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285246.txt
Further progress down to 285,232. As in #160, this was again completely self-generated by the algorithm, using a lateral move followed by an adjustment.
http://math.mit.edu/~drew/admissible_26024_285232.txt
This is the Schinzel paper? https://eudml.org/doc/206115
Or maybe this: http://matwbn.icm.edu.pl/ksiazki/aa/aa7/aa711.pdf
The citation from the ANTS paper mixes the two.
I gave a link to the Schinzel paper, but it did not show up, maybe because I gave too many links and spambot initiated?
http://matwbn.icm.edu.pl/ksiazki/aa/aa7/aa711.pdf
The ANTS citation is a bit garbled, citing the original paper (joint with Sierpinski), not the later commentary on it.
The algorithm did it’s job overnight and produced a new record for k0=26,024 with diameter 285,210.
http://math.mit.edu/~drew/admissible_26024_285210.txt
Possible new target (as of yet unconfirmed) of k0=23283, from Harcos improvement to Selberg sieve (turns out better than Pintz, in applicable range).
Just confirmed v08ltu’s calculations that 23,283 is good.
A “cheap” result 254502 for k_0=23,283 : )
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_23283_254502.txt
The algorithm stuck for a while at 253118:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_23283_253118.txt
I just kicked off a search for 23,283, I’ll resist the urge to post a flurry of sequences and wait until things at least temporarily stabilize (but I can say that it is already down below 253,500).
In the meantime, I thought I’d mention that I tried running the new algorithm which interleaves iterated merging and adjustments along the lines of #143/#154 (which I will write up shortly on the new wiki page) with k0=34429 where we had previously worked pretty hard on getting H down to 386,750. The new algorithm was able to improve this to 386,532:
http://math.mit.edu/~drew/admissible_34429_386532.txt
I’m still making progress, but I go ahead and post this in case it helps xfxie get unstuck. Diameter 253,050.
http://math.mit.edu/~drew/admissible_23283_253050.txt
It found an easy improvement to 253,048, but things seem to be stabilizing there for the moment. I also want to try running the algorithm again with a substantially different starting interval.
For reference, this run started with the interval [-135,720,118,206] finding an admissible sequence of diameter 253,926 and was able to work this down to a sequence in [-135,452, 117,496] with diameter 253,048 in fairly short order.
http://math.mit.edu/~drew/admissible_23283_253048.txt
Just a bunch of comments of varying kinds:
—
1) Sometimes a very cheap improvement can be obtained as follows (I don’t know to what extent this is already part of Drew’s / xsie’s / pedant’s local optimizations). You start from a given admissible tuple, and to the left of it you start looking for numbers that factor as a power of 2 times a large prime. Because of the way we sieved, there is some chance that adding such a number doesn’t mess up the admissibility (but there definitely is a chance that it does, too!). If there you are lucky, there might be quite a few such numbers in the near vicinity. Once you’ve collected these numbers, you start removing those that mess up the admissibility. Then you hope that enough such numbers remain, and that removing the same amount from the right shortens the diameter.
(Of course you can try the same from the other end.)
I’ve experimented a little bit with this. If you apply this to Drew’s previous post, you get a sequence of diameter 253044. One adds the first 14 such numbers to the left, then a sieve removes one of them. By removing 13 from the right you get the sequence.
—
2) Maybe a negative comment on the sieving of 1 mod 2 and 0 mod p (for p up to about the square root of the interval width). While it is true that every admissible set admits a shift that satisfies these sieving conditions (and that hence, in principle, can be found using the algorithm of #116, I guess), every such shift may lie quite far from the origin.
Example: A quick computation shows that the minimal diameter of an admissible 14-tuple is 50, and that this 14-tuple is unique up to shifting and/or flipping horizontally: ) are 116 (to the right) and 94 (to the left).
) are 116 (to the right) and 94 (to the left).
$\latex \displaystyle{ [0,2,6,8,12,18,20,26,30,32,36,42,48,50] }$.
The minimal distances over which one has to shift this set so that it consists of even numbers coprime to 3, 5 and 7 (the primes less than
In general I’d guess that one has to shift over a fairly random number modulo

(with $B$ the interval width), which can be scaringly big. So while the algorithm seems to do a good job in finding admissible sets with a small diameter, it seems unlikely that it will find an optimal set (not that we were expecting that it would, but maybe it’s useful to see this illustrated with an example).
Challenge: can we improve (or at least confirm) one of the bounds of Engelsma’s tables, e.g.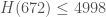 ?
?
—
3) Here are some new graphs on the behaviour of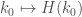 . As remarked in #59, extrapolation might be dangerous. But assuming that
. As remarked in #59, extrapolation might be dangerous. But assuming that 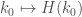 does not behave too
does not behave too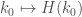 is an increasing function, at least, so it cannot jump around too much.
is an increasing function, at least, so it cannot jump around too much.
exotically in our region of interest, maybe this can assist us in guessing good target diameters in #116.1). Note that
Engelsma’s proven values for up to 372.
up to 372.
Extension including Engelsma’s upper bounds up to 672.
Entension including our current best values for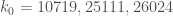 .
.
—
4) Here’s a histogram showing the number of admissible 8-tuples (up to shifting) per diameter. As you see, diameters divisible by 6 allow for significantly more admissible tuples (the histogram is for k=8, but the picture was similar for each of the few small ‘s I’ve tried. Also, (slightly) over half of Engelsma’s proven values of
‘s I’ve tried. Also, (slightly) over half of Engelsma’s proven values of 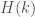 are divisible by 6.
are divisible by 6.
Is there a theoretical reason for this? Maybe observations of this kind can be used to make better guesses in the randomized steps of the algorithm (although I don’t see how, I must admit)?
Here’s a better sequence I got by starting in a slightly different region, although the algorithm eventually shifted it near to the same region as the sequence above. With diameter 252,990.
http://math.mit.edu/~drew/admissible_23283_252990.txt
Great! Seems (252990/23283) is already smaller than (285,210/26,024).
But the real comparison I think is 285210 vs 26024*log(26024) and similarly with 252990 vs 23283*log(23283), here the previous is slightly better (7.80% bloat vs 8.06%).
The thing from #173.1 does not work for Drew’s latest record. (I guess it will rarely do for sets on which the algorithm of #116 ran long enough.)
@xfxie, sorry for misprinting your name!
@v08ltu: agreed, the log factor is needed. But I think there is still a fair bit of room for improvement at k0=23283. The new run broke through 252990 a little while ago (I’ll post an updated sequence shortly, and the process that I left cranking on the 253048 sequence is down to 253000. We’ve only been at this for a few hours, it will probably be at least a day or two before things stabilize. And there are still a number of local optimizations that have not been fully explored.
New record with diameter 252,976:
http://math.mit.edu/~drew/admissible_23283_252976.txt
@v08ltu: Thanks for the correction.
BTW: I am wondering if there are any hints in theory for finding intervals with more promising solutions.
Benchmarks for k0=23,283:
Zhang with m=597 has diameter 268,536
http://math.mit.edu/~drew/admissible_23283_268536.txt
Hensley-Richards with m=635 has diameter 262,794
http://math.mit.edu/~drew/admissible_23283_262794.txt
Asymmetric Hensley-Richards with m=632 and i=12107 has diameter 262,566
http://math.mit.edu/~drew/admissible_23283_262566.txt
@xfxie: When I did an initial scan of [-400000,400000] checking every 1000 or so these are the intervals I found where the original greedy-greedy algorithm got a diameter better than 254,100
k0=23,283
[-147718,106376] 254094
[-147362,106618] 253980
[-147068,106958] 254026
[-146768,107252] 254020
[-145298,108776] 254074
[-145016,109078] 254094
[-144712,109358] 254070
[-137818,116198] 254016
[-137476,116548] 254024
[-137204,116836] 254040
[-136564,117466] 254030
[-136288,117778] 254066
[-135578,118348] 253926
[-135418,118568] 253986
[-135118,118906] 254024
[-134494,119524] 254018
[-131764,122228] 253992
[-119512,134548] 254060
[-118894,135154] 254048
[-118576,135428] 254004
You can see that there are basically three regions that look worth exploring (although if you run with a higher threshhold you might find more).
@andrew: Thanks! The results of your scanning test are very interesting. I am wondering if anybody could have some explanations on the solution clusters.
In view of #173 I added k_0 \log k_0 + k_0 as a benchmark to the wiki; I think it is somewhat of a coincidence that the best fit of the (scant) data we have is close to this particularly simple expression, but nevertheless it could serve as a benchmark.
I guess, in that vein, we could also reinstate the 10,719 data as another column to this table even though we can’t actually reach that value of k_0 any more, and maybe also keep going by approximately powers of two until we reach Engelsma (e.g. 5000,2000,1000) in order to get some idea of how various things scale with k_0. Presumably each time we halve the value of k_0, all the algorithms speed up by a factor of 2 or more, so perhaps these would be quite quick to implement? (We could also use these smaller values of k_0 to start predicting how fast various algorithms would be for realistic values of k_0,how long they take to stabilise, etc..)
Engelsma’s H(672) <= 4998 wasn't hard to beat using these methods. I've put an example of diameter 4926 in the dropbox.
Oops! Bug in code. I retract #186.
I left 3 copies of an “improved” version of the algorithm running over night (one for each region identified in #183) that implements a more general version of the “adjustments” described in #143/#154, as described in the Local optimizations section of the wiki. I put “improved” in quotes because I just found a bug that prevents it from finding all the adjustments that it possibly could. Nevertheless it made good progress in all three of the regions identified in #183, finding the following sequences:
(1) Diameter 252,952 in the interval [-117848,135104]
http://math.mit.edu/~drew/admissible_23283_252952.txt
(2) Diameter 252,918 in the interval [-145102,107816]
http://math.mit.edu/~drew/admissible_23283_252918.txt
(3) Diameter 252,804 in the interval [-135208,117596]
http://math.mit.edu/~drew/admissible_23283_252804.txt
To be fair, the sequence in (3) is in the region I started searching first, so it has had more time to run. Using a more general adjustment procedure improves the results, but it slows down the algorithm considerably (there are several optimizations I want to make as soon as I get the chance), which means it takes a lot longer to stabilize. My guess is that the algorithm will continue to make slow but steady progress in all three areas for a while yet (especially once I restart it with the bug fix).
@pedant: I did a quick run with k0=672 and the best I have so far is 5026. You might take a look at the sequence and see if you can find some obvious (or not so obvious) improvements. Looking closely at the situation with a small value of k0 might help to inform our strategy for more sophisticated adjustments.
http://math.mit.edu/~drew/admissible_672_5026.txt
Regarding #185, I think this is a great idea. I would also suggest including one or two larger values of k0 to get a better sense of how things scale. And I think it would be worth adding a row for the original greedy-greedy algorithm (with ties broken toward zero) for comparison, since this will give a better sense of how much the iterated merging and local optimizations are buying us. I can generate data to fill in most of these, but I need to take the time to streamline my code a bit to better automate the process. I can do this today.
I also plan to fill in the Schinzel row, but I need to change the program, right now it just sieves positive integers and this gives a value that is usually the same as Zhang’s, not even as good as Hensley-Richards. I need to move the interval around (or at least use an interval centered on the origin).
I did do a greedy-greedy scan with k0=181000 (which took a while), and I believe the optimal interval is [-2444558,-98662], which yields a sequence of diameter 2,345,986, a substantial improvement over Pintz’s 2,530,338. Here is the sequence for reference:
http://math.mit.edu/~drew/admissible_181000_2345896.txt
Regarding Edelsma/672: interestingly, I let my code run during the night (starting from an admissible set of width 5250 centered roughly symmetrically around the origin) and the best diameter it found was 5030, almost exactly on top of the 5026 that you found (minimum of 926 instead of 922). Yes, I was planning to do exactly as you suggest in #189.
OK, I’ve added several new columns to the benchmarks table to cover multiple orders of magnitude, from Pintz to Engelsma. Lots of blanks to fill!
@Terence: I’m on it. Here’s the data for k0=5000 and k0=10719, which I list here just so we have a record of the values of m and i that were used. I’ll put the sequences in the table
k0=10719
114,806 Zhang m=331
112,868 HR m=362
112,646 aHR m=362, i=295
108,694 gg
108,462 best (note, this beats the old record of 108,514)
k0=5000
49,578 Zhang=223
48,634 HR m=202
48,484 aHR m=198, i=3
46,968 gg
46,824 best
As noted above, I still need to implement the Schinzel case. For both these values of k0, the convergence of the iterated-merging-plus-adjustments algorithm was quite quick, within 10-20 minutes.
Caveats: for the asymmetric HR cases, I did not test every combination of m and i, but I believe the values listed are optimal (I can guarantee that i is optimal for the given m). And in both of the “best” cases, I only searched in the interval that was optimal for gg.
By starting with a different interval I was able to get the k0=672 case down to diameter 5010
http://math.mit.edu/~drew/admissible_672_5010.txt
The new sequence lies in the interval [454,5464], where as the diameter 5026 sequence was in [922,5948]. What’s interesting is that the initial scan with the greedy-greedy algorithm did not look very promising around [454,5464] with diameters around 5060 or 5070, versus 5030-5040 around [922,5948].
So, at least in this example, it’s not necessarily optimal to be searching in the interval that looks the best on initial inspection. Something to keep in mind relative to #183.
@Andrew: Thanks for all the data! Interesting to see a crossover between Zhang and Hensley-Richards for small values of k_0, it suggests that some of our older methods may be worth revisiting as k_0 decreases.
I separated the Engelsma data onto another row. I am thinking of also adding the simplest sieve of all, the “first k_0 primes after k_0” sieve (which is actually the one that Zhang used, if one wants to split hairs); it’s of course going to be worse than all the other sieves, but has the advantage of being the shortest to actually describe (and to verify the admissibility of).
@Terence: More data to come, the only thing stopping me from filling in the asymmetric HR and Schinzel rows is that I have gotten distracted by trying to match (or beat) Engelsma’s records. I just matched his bound for k0=3000.
I went ahead and widened the table to include 3000 and 4000, I hope you don’t mind. I think seeing the full comparison with Engelsma’s data is interesting, since his techniques are very different. I find it reassuring that we seem to be getting very close his values, and without a lot of effort (It took only a few minutes for the algorithm to find the 3000-tuple of diameter 26,622).
This page by Engelsma, though 3 years old, probably deserves a link (on the wiki).
http://www.opertech.com/primes/k-tuples.html
Oh, I found the link on the wiki now, it was on the Bounded Gaps page, not the Finding Narrow Admissible Tuples page, sorry
We’ve managed to get a small improvement in k_0, from 23,283 to 22,949. (Actually there was a technical issue in the justification of the previous k_0 which is what ultimately led to the improvement, although this is now moot since the new value of k_0 is better and the justification is not subject to this problem.)
This is a bit lame, but due to the small difference, just taking the best 22949-subtuple of Drew’s previous 23283-record should already be a good first benchmark (e.g. the elements on positions 278, 279, …, 23226 form an admissible 22949-tuple of width 249180).
I agree, truncating the 23283 record already gives a pretty good sequence. But I just found a better one in a different region
http://math.mit.edu/~drew/admissible_22949_249046.txt
Hi Drew, just out of curiosity, was this new region also a good region for the 23283 case? I wonder to what extent these good regions correlate, or whether a small difference in k_0 can already turn upside down the whole spectrum (also in view of your remark in #193).
@Wouter: It was a decent region, but not as good as others. Things can definitely move around when k0 changes.
Here is a better sequence for k0=22949 from yet another spot,
with diameter 249,034
http://math.mit.edu/~drew/admissible_22949_249034.txt
@Terence: Does it make sense to now replace the 23283 column in the table with a 22949 column? It would be easy enough for me to recompute all the entries.
@Andrew: Sure. Actually we could keep both columns for now (if we split up the first Montgomery-Vaughan entries into two lines, there should be enough space). Do I understand that your computations of the first Montgomery-Vaughan constraint differ from that of Gergely’s computations? I guess we should get to the bottom of this at some point.
In the process of filling in the table, I found a significantly better tuple for Pintz’s k0=181,000, with diameter 2,326,476.
http://math.mit.edu/~drew/admissible_181000_2326476.txt
@Terence: I’m afraid the lower bounds are my doing. The computation is different because I just used some generic routine for minimization. Later, when we settle on optimal k_0 we can change that to some grid search combined with bisection.
I’m having problems with the second M-V condition. I may be code-blind but I can’t find any mistake. Yet, the second M-V inequality is not satisfied. (I’ve rewritten it to the form -k_0*L >= -1 and I keep getting values on LHS that are well below -1.) The code is on github (https://github.com/vit-tucek/admissible_sets) if anyone wants to take a look.
I might calculate the M-V lower bounds for k0=22949 later, but for those interested I share my very simplistic SAGE code that confirms the 167860 lower bound for k0=26024.
N=Integer(167860)
k=Integer(26024)
c=(sqrt(22)/pi).n(digits=10)
R=1
T=0
for Q in [320..340]:
S=sum([(moebius(q)^2/(euler_phi(q)*(N+c*q*Q))).n(digits=10) for q in [1..Q]])
if S>T:
R=Q
T=S
print R,k*T
Is it OK to substitute just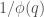 for that product of
for that product of 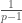 over primes that divide
over primes that divide  ?
?
Yes, because the sum is only supported on squarefree q due to the moebius(q)^2 factor.
After running the algorithm over night I was able to get the diameter down to 248,970:
http://math.mit.edu/~drew/admissible_22949_248970.txt
After experimenting some more with some of the smaller cases, I think I see a way to efficiently implement a more general version of the adjustment process described in the wiki, which may yield some further improvements (at a minimum, I see how to make the code a lot faster, which, if nothing else, will accelerate the search process).
I’ll take a stab at implementing this today to see if I can get any further improvement. I also want to try searching in a few more places (i.e. using different starting intervals).
Here are the numbers I get for some “Second Montgomery-Vaughan”-bounds.
(Have included z as it perhaps can help with verification.)
k=23283
c H z
1 153691 403
3.2/pi 153447 403
sqrt(22)/pi 148719 330
3/2 148656 330
k=22949
c H z
1 151298 403
3.2/pi 151056 403
sqrt(22)/pi 146393 291
3/2 146338 291
k=10719
c H z
1 66314 239
3.2/pi 66211 239
sqrt(22)/pi 63917 222
3/2 63886 222
However, I might be doing something wrong. For k=26024 and c=1 I get the bound 173420 (z 438). This does not match Gergely’s number.
@Hannes: You are right, and I was wrong. For k=26024 and c=1 I tried to maximize in z, but for some reason I constrained z to an interval that was too small (it did not contain 438). So all my lower bounds should be double checked! (My lower bounds are OK, but they might be sub-optimal to the method.)
I updated my program (and seems to work properly), but cannot run it right now. I will supply updated data in about 4 hours.
I was able to get a new version of the adjustment algorithm working that improves on #143/#154 and is much faster, both asymptotically and in terms of its constant factors. For k0=22949 it’s 20-30 times faster than what I was doing before. I’ll update the wiki to later to explain what I am doing (there are a few more things I still want to try). In the meantime I can post a new record with diameter 248,910.
http://math.mit.edu/~drew/admissible_22949_248910.txt
It took the new algorithm only about an hour to find this. How much of the improvement is due to using more general optimizations versus pure speed (meaning more random iterations) isn’t completely clear, but I think it’s some of both — it didn’t get down to 248910 in one fell swoop, it took several small jumps with a lot of random probing in between. I didn’t get any immediate improvement when I ran it against some of the older cases that have already been heavily optimized, but I will let it run for a while on some of the smaller examples in the table to see what happens.
All the bounds found by Hannes were confirmed by my new SAGE program. I discovered that 4 of my earlier M-V bounds were incorrect due to the fact that I restricted z too much. The corrected numbers along with new M-V bounds missing from the table are as follows:
k=34429
c H z
1 234872 474
3.2/pi 234529 474
k=26024
c H z
1 173420 438
3.2/pi 173140 438
k=5000
c H z
1 28781 146
3.2/pi 28737 146
sqrt(22)/pi 27708 123
3/2 27696 123
k=4000
c H z
1 22564 146
3.2/pi 22523 146
sqrt(22)/pi 21701 115
3/2 21690 115
k=3000
c H z
1 16456 115
3.2/pi 16428 115
sqrt(22)/pi 15758 95
3/2 15751 95
k=2000
c H z
1 10500 95
3.2/pi 10480 95
sqrt(22)/pi 10061 79
3/2 10056 79
k=1000
c H z
1 4858 70
3.2/pi 4847 70
sqrt(22)/pi 4648 47
3/2 4645 47
k=672
c H z
1 3124 47
3.2/pi 3118 47
sqrt(22)/pi 2979 42
3/2 2977 42
I got these numbers for “First Montgomery-Vaughan”. Some bounds differs from what is currently in the table.
k: 34429, 26024, 23283, 22949, 10719, 5000, 4000, 3000, 2000, 1000, 672
H: 197096, 145711, 128971, 126931, 55178, 24037, 18859, 13696, 8615, 3959, 2558
Q: 123, 115, 115, 115, 78, 43, 43, 42, 35, 23, 15
Also, I believe the missing Brun-Titchmarsh-bound (k=22949) for should be 135599.
A new record for k0=22949 with diameter 248,898:
http://math.mit.edu/~drew/admissible_22949_248898.txt
Regarding Wouter’s comment (2) in #173, the new algorithm is now able to improve on Engelsma’s bound for k0=3000, achieving H(3000) <= 26610, versus 26622. My guess is that there are other cases where his bounds can be improved. I also got a small improvement for k0=1000, down to 7006, but this is still 4 above Engelsma's bound.
A comment about the implementation mentioned in #215 that is also pertinent to #173. One can view the algorithm of #116 as a 2-stage optimization process. The first stage is in step (2) where the target interval is selected. In fact this really amounts to fixing a choice of residue classes to sieve [0,x] for primes smaller than sqrt(x): if the chosen interval is [s,s+x], then we are sieving [0,x] by s mod 2 and 1-s mod p, and then proceeding greedily after that. From an implementation point of view, its nicer to view things from this perspective — the implementation is cleaner and faster. I've updated the wiki page to better reflect this perspective.
One optimization I am using in the step where s is chosen is not carrying the sieving process to completion, e.g. just optimize the survivors left after sieving for p <= sqrt(x), or after sieving greedily a bit further but still well short of k0 (NB: the bound, sqrt(x) is not necessarily the optimal choice, but it is intuitively the right order of magnitude and seems to work well in practice). This speeds things up substantially, allowing you to test more values of s.
As Wouter noted in #173, for any choice of residue classes there is an s that works, but this s might be very large (potentially as large as the product of the primes up to sqrt(x)). But rather than picking s in some relative small interval (I currently use something on the order of [-k0 log k0, k0 log k0]), one can consider other ways of picking the initial set of residue classes at small primes. My guess is that those that correspond to small values of s are likely to be good choices, in general (and the fact that we are already able to get quite close to Engelsma's bounds supports this), but one can also consider small perturbations of such a choice. This is something I am currently working on.
More “Second Montgomery-Vaughan”-bounds:
k=3500000
c H z
1 32503908 5731
3.2/pi 32469985 5523
k=181000
c H z
1 1395694 1195
3.2/pi 1393869 1195
Also; should I replace (in the wiki) the “First Montgomery-Vaughan”-bounds found by Gergely and Vít that are weaker than the ones I listed in my previous post? Maybe someone can check if I screwed up somehow?
I added a note regarding the Zhang tuples to the table on the wiki, explaining that in some cases an m slightly larger than the minimal m that produces an admissible k0-tuple yields a narrower tuple. For the record, here is a list of minimal and optimal m < pi(10^10) for each of the k0 in the table, listed as k0, min m, opt m < pi(10^10):
672, 48, 48
1000, 60, 66
2000, 93, 93
3000, 139, 139
4000, 162, 162
5000, 213, 223
10719, 326, 331
22949, 586, 599
23283, 596, 597
26024, 655, 655
34429, 825, 836
181000, 3056, 3056
3500000, 33639, 33639
I was also able to improve the best known admissible tuple for k0=34429 using the new algorithm, bringing the diameter down to 386,460.
We now have H(34,429) <= 386,432:
http://math.mit.edu/~drew/admissible_34429_386432.txt
Hi, I derived better lower bound for H(k) using the work of Engelsma, and an algorithm based on inclusion-exclusion to lower bound H(k).
The details can be found here:
Click to access Primes.pdf
The lower bounds which I got are:
H(672) >= 4574 (Due to Engelsma’s results)
H(1000) >= 6802 (Due to Engelsma’s results)
H(2000) >= 14082 (Inclusion-Exclusion)
H(3000) >= 21884 (Inclusion-Exclusion)
H(4000) >= 29746 (Inclusion-Exclusion)
H(5000) >= 38048 (Inclusion-Exclusion)
H(10719) >= 85878 (Inclusion-Exclusion)
H(22949) >= 193330 (Inclusion-Exclusion)
This lower bounds (especially for greater k_0) can be improved significantly with more computation.
And here are some other lower bounds.
k=3500000
Second Montgomery-Vaughan, c=sqrt(22)/pi
31765216 (z 4543)
Second Montgomery-Vaughan, c=3/2
31756667 (z 4543)
First Montgomery-Vaughan
28080007 (Q 1374)
k=181000
Second Montgomery-Vaughan, c=sqrt(22)/pi
1357096 (z 943)
Second Montgomery-Vaughan, c=3/2
1356644 (z 943)
First Montgomery-Vaughan
1184954 (Q 291)
For k=181000, I got a lower bound of 1513556
For k = 3500000, I got a lower bound of 29508018
Both are derived from the upper bounds on the maximal size of admissible set within a fixed size interval presented in the pdf file above.
My python code can be found here:
https://sites.google.com/site/avishaytal/files/polymath8_lb.py
The function Md_upper_bound gives an upper bound on the maximal size of admissible set withing a fixed interval length.
The function calc_Md_table, combines previous results using dynamic programming to get new bounds.
The simple relation M(d)=d gives immediate lower bounds for H(k).
Typo: I meant “the simple relation M(d)=d gives…”
Problems with html and less than equal.
“the simple relation M(d) less than equal k-1 iff H(k) greater equal d gives…”, phew.
This is very preliminary and needs to be confirmed, but it looks like we may soon have a much better bound for k0.
http://terrytao.wordpress.com/2013/06/14/estimation-of-the-type-iii-sums/#comment-234677
While I suspect there may be further tweaking of the value k0=6330 in v08ltu’s post, I note that this would already put H well under 100,000.
As an initial bound that I’m sure can be improved, we we can say that H(6330) <= 60830.
http://math.mit.edu/~drew/admissible_6330_60830.txt
I see the bound on k0 was already improved by Harcos to 6329 while I was typing #229. Leaving out the first point in the sequence above brings the bound down to 60,812.
http://math.mit.edu/~drew/admissible_6329_60812.txt
I just updated my software during the weekeed, and found a solution:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_6329_60788_-67218.txt.
A new one is 60778:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_6329_60778_-67276.txt
Another new one is 60764 for k0=6329:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_6329_60764_-67290.txt
For k0=6330, the current solution is 60772:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_6330_60772_2836.txt
If cut the head point of #234, the solution will be 60762. But the software found a new solution 60760.
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_6329_60760_-67438.txt
For the empty lower-bound-fields (k=6329):
Second Montgomery-Vaughan
c H z
1 37274 195
3.2/pi 37207 195
sqrt(22)/pi 35903 146
3/2 35887 146
Brun-Titchmarsh
32916
First Montgomery-Vaughan
H Q
30982 47
I left the program running overnight and was able to get H(6330) <= 60760
http://math.mit.edu/~drew/admissible_6330_60760.txt
Removing the first point yields H(6329) <= 60756
http://math.mit.edu/~drew/admissible_6329_60756.txt
Oops, removing the last point from the 6330 sequence in #237 is better, this gives H(6329) <= 60744
http://math.mit.edu/~drew/admissible_6329_60744.txt
H(6329) > = 48776
H(22949) >= 193420
using inclusion-exclusion algorihtm with exhaustive search parameter = 13.
For 6330, there is a new solution 60754:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_6330_60754_2854.txt
For 6329, the algorithm found the same H as #238, but in a different place:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_6329_60744_-67422.txt
@xfxie: it’s great to see that we are getting matching bounds (I just got 60754 for 6330 too, but like yours, it doesn’t improve the 6329 bound). I’m now curious to try generating sequences for values of k0 slightly larger and slightly smaller than 6329 and seeing if the results can then be tweaked to get a better bound for H(6329).
In your new implementation have you added any new types of optimizations?
One thing I have changed is allowing non-improving (“plateau”) moves in the adjustment phase, as I do in the merging phase. This seems to help it find a solution more quickly, but not necessarily a better one than it could have found otherwise. I have also extended the “shifting” test (as in #144) to look a bit farther and made it a standard step in the main loop (with k0 down to 6329, one can afford to try a lot more things). Here I also allow non-improving moves.
@andrew: Yes, sometimes solutions might be easily available by modifying solutions with slightly larger or smaller k0.
There are some changes in the new version:
1. Taken starting points as an 1-D search dimension: (a) allow the solutions for large lateral moves, with an acceptance function based on the cost difference. (b) add a database to index all best solutions on all starting points, and choose them later as incumbent or reference solutions, based on both their H values and locations. (somewhat based on the observation in #183)
2. Added more local search operators: (a) remove both head and tail points as searching in plateaus; (b) exchange more than one pair of “slots” based on the cost calculation. (also added your greedy removing strategy as a choice for repairing inadmissible sequences.)
3. Also added/modified some auxiliary data structures to accelerate the computation.
Just to report a new solution 26606 for k0=3000:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3000_26606_-29486.txt
@xfxie: Excellent, I assume you are checking the others with your new algorithm? It would be nice to be able to match/improve the Engelsma bounds for the other cases — given how much we have gained at 3000, I would think we ought to be able to improve his bound at 4000.
I did get some further improvement for k0=34429, down to 386,382.
http://math.mit.edu/~drew/admissible_34429_386382.txt
The Polymath wiki will be briefly down this morning, for a little required maintenance. Shouldn’t take more than an hour or so, from 10am EST (US).
@andrew: I have checked those with small k0 values, and obtained solutions with the same H values as yours, although they are in other locations. I just list them here, in case of somebody might want to look for more problem features in “good” solutions.
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_672_5010_-5464.txt
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1000_7806_-8564.txt
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_2000_16984_-18092.txt
I did found a new solution 46810 for k0=5000:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5000_46810_3946.txt
The wiki is back up. Let me know if you notice any strange behaviour.
@xfxie – There was a brief period of time (< 30 seconds) between when I initiated a backup and when I locked down access to the wiki. Unfortunately, you made a small edit during that time. That edit has been lost, and will need to be re-entered. My apologies for making this mistake (I should have locked it down first).
@Micheal – Thanks. I have re-entered the minor change (putting the solution 46810 for k0=5000) .
Just updated k0=10719 from 108,462 to 108,450.
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_10719_108450_-116422.txt
Here is an initial sequence for k0=3405, with diameter 30,610
http://math.mit.edu/~drew/admissible_3405_30610.txt
Here’s a better sequence for k0=3405 with diameter 30,600:
http://math.mit.edu/~drew/admissible_3405_30600.txt
I note that H(3405) <= 30,600 is better than the bound of 30,606 given by the Engelsma data.
Some bad news: the improvement I had proposed that would have led to k_0 = 3405 fell through, so we’re back to k_0 = 6429 for now. Sorry about that…
Er, 6329, I mean.
No problem, it’s a good exercise to test the algorithm on different values of k0. And it’s basically all automated at this point.
@andrew: Regarding to the post #244, there is indeed a new solution 36612, which is better than the Engelsma bound, for k0=4000:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_4000_36612_2554.txt
@xfxie: Excellent. And I just posted a new tuple for k0=1000 that matches the Engelsma bound of 7802.
http://math.mit.edu/~drew/admissible_1000_7802.txt
This was enabled by fixing a bug I found in my program that was causing it to miss some adjustments. The bug fix also allowed me to match your bounds for k0=3000 and k0=5000. The new sequences are substantially different from yours, so I post them here in case they are useful to you:
http://math.mit.edu/~drew/admissible_3000_26606.txt
http://math.mit.edu/~drew/admissible_5000_46810.txt
The shift for the 3000 sequence is 1262 and the the shift for the 5000 sequence is 3946.
So now 672 and 2000 are the only entries with *’s on them.
@andrew: That’s great.
I found the solution for k0=1000 in another region as well:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1000_7802_764.txt
BTW: I have tried to run some small instances to gain more sense of the algorithm performance, as shown below. It seems that the algorithm perform well from 100 to 500. But it cannot get a good result for k0=600. Maybe you could try your algorithm to find better solutions.
#k0, Engelsma bound, current solution
100 559 http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_100_558_-370.txt
200 1267 http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_200_1268_-844.txt
300 2011 http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_300_2010_-2264.txt
400 2791 http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_400_2792_-2194.txt
500 3595 http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_500_3594_-4208.txt
600 4381 http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_600_4412_542.txt
Just found 16,978 for k0=2000:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_2000_16978_1108.txt
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_2000_16978_1114.txt
Found a new solution 60740 for k0=6329:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_6329_60740_-63166.txt
@xfxie: Congrats! I was beginning to think we might be stuck at 60744. Did you make any changes to your algorithm to find this, or was it just a matter of giving it more time?
Regarding #258, I note that the Engelsma bounds you list are all off by 1 (by parity considerations, H(k0) is even for all k0>1). He uses a different convention for width (his tuples are all of the form x+1,…x+w and he reports w, but the diameter is w-1). For k0 <= 342 his bounds are known to be optimal, so your sequences for 100 and 300 are best possible, and at 200 you are only off by 2 (and I currently get the same diameter 1268 as you, versus the optimal 1266).
For k0=342 I was able to match the optimal bound of 2328 with
http://math.mit.edu/~drew/admissible_342_2328.txt
For k0=400,500,600,700,800 I was able to match Engelsma's bounds (your sequence for k0=500 also does this)
http://math.mit.edu/~drew/admissible_400_2790.txt
http://math.mit.edu/~drew/admissible_500_3594.txt
http://math.mit.edu/~drew/admissible_600_4380.txt
http://math.mit.edu/~drew/admissible_700_5246.txt
http://math.mit.edu/~drew/admissible_800_6096.txt
At k0=900 I was able to do better than Engelsma's bound of 6950, obtaining H(900) <= 6944 (this is the smallest k0 for which this is the case so far);
http://math.mit.edu/~drew/admissible_900_6944.txt
New bound: H(6329) <= 60,732.
http://math.mit.edu/~drew/admissible_6329_60732.txt
An amusing anecdote relating to post #262: I just finished giving an interview to the M^3 (MIT Math Majors) magazine, who were aksing about the prime gaps polymath project. I was in the process of explaining how we were using randomized optimization algorithms to search for better bounds on H and mentioned that I currently had the algorithm running on my laptop. I then went to check the output directory and found that it contained a new record! I went ahead and posted the new result during the interview.
Needless to say, the interviewer was very impressed :)
On a more serious note, I think this project is a great way to promote mathematics. Letting everyone see the developments in real time (and participate if they wish) has added a lot of excitement to what many tend to think is a very slow moving field.
New bound based on #261:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_6329_60726_14.txt
@xfxie: Excellent! This is exactly what I told the interviewer would happen :) By posting our ideas and solutions in real time we collectively make progress faster than any individual could.
@andrew: That’s right. Also saved a lot of computer time!
It looks like Pintz has sent an argument to Tao which “morally” leads to the better bound $\latex 87\varpi \leq 1/4$. Assuming this works out, what is the new value of $\latex k_0$?
For those of us who got into the game a little late, is there a link to the currently optimized code for gap searching?
Note on the k0=900, the value shown in the summary file is 6945 (your 6944) believe you subtracted 1 from the k0 value because k0=901 is 6951 (your 6950)
Loaded up the program(s), and attempting to recreate the searching
Started with k0=3405 your w=30600 and was able to generate over 1200 unique patterns before hitting the stop. I would venture to say 30600 can be improved to 30588 if the elusive pattern could be found.
These programs target by width (diameter), and looking how to convert the code to target k0.
Is there a specific k0 of interest ??
@Thomas: You are right, I read the wrong line in your file. Thanks for the correction! So I believe this means the least k0 where we have been able to improve your bounds still stands at 3000 (26606 vs 26622).
The specific k0 that is currently of interest is 6329. But we are hopeful that this may come down soon. If it comes down to 342 or lower, then we are effectively done: your tables give an optimal bound on H(k) for all k up to 342. But I have no idea if or when that will happen.
If I read your web-page correctly, your results also give some sporadic optimal values for some larger k, e.g. H(369)=2528 and H(384)=2654, where H(k) denotes the minimal possible diameter (difference between largest and smallest element) of an admissible k-tuple. Is that correct?
@Pace: v08ltu or Gergley Harcos are the right people to answer your first question. Regarding code, you can download reasonably fast C code for my original “greedy-greedy” algorithm at
http://math.mit.edu/~drew/admissable_v0.1.tar
I believe the current records are all being set using optimizations of this algorithm, as described above in this comment thread and summarized on the wiki. If you are a C programmer it should be pretty easy for you to work from the code above as a base. It’s certainly no work of art (I wrote it in a hurry), but it’s straight forward enough.
I am currently in the process of re-working my code. It’s a mess at the moment and has a nasty habit of randomly seg-faulting. There is also a lot of dead code in places where I tried things that didn’t seem to work. It really needs to be rewritten from scratch once things settle down (i.e. k0 stays stable for more than a few days).
When I have a version that is fit for human consumption I will post an update, but in the mean time I would encourage you to try your own hand at it. There is definitely still room for improvement and you may come up with tweaks that none of us are currently using. A diversity of implementations is a good thing. I believe xfxie and I are both using the same basic approach, but we each have our own implementation and it’s often the case that one of us is able to make progress when the other appears to be stuck.
H(6329) >= 49464
using inclusion-exclusion algorihtm with exhaustive search parameter = 17. I actually improved the bound slightly algorithmically by a ~1/300 fraction.
Just using engelsma’s result for H(k0) k0 <= 342, the lower bound is 43130
@Avishay: Assuming Thomas confirms H(369)=2528 and H(384)=2654, can you use these to improve your results?
I think it makes sense to add two more rows to the table on the wiki to record your bounds (I also want to add a column for 342, since this is a critical value for k0). But I want to make sure I understand the values you list in the table as “Engelsma Lower bounds” in your document listed in #223. How are you partitioning k-1? In your example in section 1 you use 672-1=335+336 to get H(672) >= 2270+2286=4556, but there are other choices. e.g if I instead use 672-1=332+339 I believe I get H(672) >= 2310+2256 = 4566, and in your table you list H(672) >= 4574. When k is large choosing the optimal partition seems hard — how did you derive the values in the Engelsma column in your table? And are the bounds in #255 obtained by partitioning or inclusion-exclusion?
(Answering for Thomas in case he doesn’t check in for a while.) When I emailed him last week, he confirmed that some of the values beyond 342 are optimal, as you say. But I think his claim is dual to the one you make in #269 — that is, the maximum admissible subset of a set of width 2528 has size 369, rather than that the minimum width of an admissible set of size 369 is 2528.
@pedant: Yes, I think you must be right. This does then imply H(370) >= 2529 (and similarly H(385) >= 2655), which might still be useful for proving other lower bounds (e.g., via partitioning), even if these bounds are probably not tight.
pedant, thanks for the clarification !
Yes, H(369) and H(384) are valid exhaustive search values.
The diameters 2528 and 2654 were exhaustively searched as these were crossover points where k(w)=pi(w).
Many (most) diameters less than 3158 were searched for k0+1 elements, but produced no patterns, so they were of no interest at the time and not recorded (who knew ?). The way you are using the numbers it would have been of great value to record. But I have no hard record of it, sorry.
@Andrew
Specfically for 672 the partition I took is 672-1=331+340 which gives H(672)>=2252+2322=4574.
In general I used dynamic programming to upper bound what I referred to as M(d) (and is refered here as rho(d)).
Assume you have upper bound for M(i) for all i342: It seems it improves the lower bounds obtained, especially as k is larger.
In the following table:
k, Lower bound based on k<=342, Lower bound based also on k in {369,384}
672 4574 4574
1000 6802 6804
2000 13620 13702*
3000 20434 20678*
4000 27248 27514*
5000 34068 34470*
6329 43130 43614*
10719 73094 74018*
* For these k, Inclusion-Exclusion bounds are better than the ones derived by Engelsma's table.
In #225 I used Inclusion-Exclusion to give the bounds.
@Avishay: got it, thanks! Note that per #273, we actually only have (not necessarily tight) lower bounds on H(370) and H(385), not exact bounds on H(369) and H(384), sorry for the confusion.
I updated the table on the wiki to include two new rows of lower bounds, one for inclusion-exclusion, and one for partitioning.
It would be great if you could take a look at the table in the wiki
http://michaelnielsen.org/polymath1/index.php?title=Finding_narrow_admissible_tuples#Benchmarks
and check that I have filled in the values correctly (please feel free to make corrections directly, and to fill in blank entries — even in cases where inclusion-exclusion isn’t as good as partitioning, it’s interesting to see the comparison).
I also added a column for k0=342, since this is the first place where we have lower and upper bounds that match (due to Engelsma). I note that the upper bound on H(342) can also be achieved using the techniques we have developed here:
http://math.mit.edu/~drew/admissible_342_2328.txt
@Pace: v08ltu already did a calculation at http://terrytao.wordpress.com/2013/06/14/estimation-of-the-type-iii-sums/#comment-234752 that suggests that the theoretical limit of all this and
and  optimisation is
optimisation is  with the currently available Type I/II and Type III estimates. Pintz’s argument (just posted on my blog) won’t quite get to that level but it should get reasonably close. But there should be a bigger improvement coming in a few days because apparently Fouvry, Kowalski, and Michel have a much better way to do the Type III sums, but I don’t yet know the full details (it will probably be comparable to the false alarm we had a few days ago when I thought I had improved the Type III sums and gotten
with the currently available Type I/II and Type III estimates. Pintz’s argument (just posted on my blog) won’t quite get to that level but it should get reasonably close. But there should be a bigger improvement coming in a few days because apparently Fouvry, Kowalski, and Michel have a much better way to do the Type III sums, but I don’t yet know the full details (it will probably be comparable to the false alarm we had a few days ago when I thought I had improved the Type III sums and gotten  down to 3,405). So there is going to be a certain amount of progress for
down to 3,405). So there is going to be a certain amount of progress for  coming down the pipeline in the days ahead…
coming down the pipeline in the days ahead…
It looks like we provisionally have a new k0 of 5937, as calculated by v08ltu, as a “cheap” improvement derived from a theorem of Pintz (see Tao’s latest blog post for details). This is likely to be temporary, as bigger gains are expected to come from optimizing more of the parameters, but for the moment we get a new bound on H from H(5937) <= 56660.
http://math.mit.edu/~drew/admissible_5937_56660.txt
Actually, here is a better tuple for k0=5937, with diameter 6,640.
http://math.mit.edu/~drew/admissible_5937_56640.txt
Not fully confirmed yet, but we now have a likely value of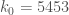 , which is surprisingly close to the theoretical limit of 5446 mentioned earlier. The Pintz sieve is very efficient! And also robust – it looks like one can be a bit lossy with the various kappa errors in that sieve and the 5453 bound above will still survive.
, which is surprisingly close to the theoretical limit of 5446 mentioned earlier. The Pintz sieve is very efficient! And also robust – it looks like one can be a bit lossy with the various kappa errors in that sieve and the 5453 bound above will still survive.
H(5453) <= 51,544
http://math.mit.edu/~drew/admissible_5453_51544.txt
A slightly better tuple (diameter 51,534) using a substantially different shift offset.
http://math.mit.edu/~drew/admissible_5453_51532.txt
An improved version of the tuple in #281
http://math.mit.edu/~drew/admissible_5453_51526.txt
Seems I got up too late :). After running for a while, the algorithm only found the solutions that Andrew found in #279 and #283.
I could only try some tests on the current the theoretical limit 5446 as mentioned in #277, but it still cannot break 50000:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5446_51456_2452.txt
H(5453) >= 41860 using inclusion-exculsion
H(5453) >= 37224 using engelsma’s results for k = 37576 using engelsma’s results for k <= 342 and k = 370, 385.
@Avishay: Thanks,I have updated the tables to reflect these bounds. For the sake of consistency I just listed 37224 for the partitioning bound. At least in cases where inclusion/exclusion gives the better bound, I don’t think it makes much of a difference.
For 627 and 1000, does using the bounds for k=370,385 improve the partition lower bound? If so this might be worth noting.
@xfxie: There seems to be a problem with the link in #284
@andrew, thanks. Forgot to copy the file. Now it is online.
It looks like we may have to (at least temporarily) fall back to k0=5455:
http://terrytao.wordpress.com/2013/06/18/a-truncated-elementary-selberg-sieve-of-pintz/#comment-235292
In case we do, here is a sequence for 5455 with diameter 51,556
http://math.mit.edu/~drew/admissible_5455_51556.txt
Seems that k0=5455 is safer (if I understood correct about v08ltu’s new post), so here is a possible solution H(5455) <= 51,540
admissible_5455_51540_4678.txt
Seems Andrew is faster, but I forgot the link:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5455_51540_4678.txt
In fact one can do better by extending #283:
http://math.mit.edu/~drew/admissible_5455_51540.txt
@xfxie: I see our posts crossed, but I guess #290 < #291 :)
On a more serious note, I have actually been experimenting with local moves that involve extending and reducing. I've seen a few cases where you can be stuck at with a particular k0, but if you add a few admissible points at the ends, apply some adjustments, and then remove points from the ends, you can sometimes get the diameter down.
@ Andrew: What you mentioned is definitely worthy to try.
I only tried the reverse side: reduce some points, and apply some moves, and accept if there are new solutions, or repair finally if not. My observation is that it rarely leads to a better solution, but it can be seen as a good perturbation strategy for my base plateau moves, and often can be very helpful in escaping from a local optimum.
@xfxie: I have tried it both ways. I seem to have slightly better luck with extend/reduce rather than reduce/extend, but I agree that it doesn’t help that often, it’s just something to try when you get stuck.
On the off chance that we wind up at k0=5454, I note adding a point to #283 gives diameter 51536, as does removing a point from either #290 or #291 (so I hereby declare it a tie :)). But I found another 5454 solution with diameter 51536 that is in a very different spot (offset 2362 rather than 4678), which might be useful:
http://math.mit.edu/~drew/admissible_5454_51536.txt
You can actually get 51534 :)
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5454_51534_-56228.txt
Seems the main problem is still to find and evaluate feasible k0 values. I am wondering if we could try some NLP optimization software to search them, if all equality and inequality constraint functions can be explicitly defined.
@Andrew: See #275
Removing one point from #283 gives H(5452) <= 51520
http://math.mit.edu/~drew/admissible_5452_51520.txt
@Avishay: Got it, thanks (sorry I missed it the first time).
Any upper bound of the form H(k) <= n implies the upper bound H(k0) <= n-2*(k-k0) for 2 < k0 < k (removing one end point will always reduce the diameter by at least 2). For example, #283 implies H(5452) <= 51524. So I'm not sure that the bound H(5452) <= 53,672 currently listed on the wiki really constitutes a new record.
Ah, I see there is an asterix on it, fair enough.
Seems I got up late again!
I just did a systematic search from 5452 to 5446. As compared to the solution in #298(and #283) by removing tail points, seems I only got better results until 5449. It might be interesting it might interesting to see if any narrow sequences could be build from them, based on Andrew’s comment in #241.
k0 #298 Current
5452 51520 51520
5451 51516 51516
5450 51498 51498
5449 51496 51486*
5448 51484 51480*
5447 51474 51472*
5446 51460 51456* (See #284)
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5452_51520_4678.txt
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5451_51516_-55712.txt
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5450_51498_-56176.txt
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5449_51486_-56228.txt
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5448_51480_-56222.txt
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5447_51472_-56138.txt
BTW: To not let the computer being idle, I let it run on the benchmark instance k0=26024 over night, and it returned a new result:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_26024_285208_-147296.txt
Oops, just a better result 51462 came out for 5447:
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_5447_51462_-53908.txt
@xfxie: do we have k0=5447?
I get the same bound at the same offset, but slightly different internally.
http://math.mit.edu/~drew/admissible_5447_51462.txt
@andrew: Not yet. Maybe we need wait for another wave of k0 dropping, if have. Seems the optimization problem become much easier. But maybe there are some unexpectedly hard k0 instances to be met, given we still cannot exactly solve some very small cases (e.g., k0=672).
Actually, we might solve most of remaining k0s in a few days, even in a systematic way.
@xfxie: I agree, in fact I have a proposal. I think at this point rushing to solve particular k0’s is counterproductive — we both can arrive at essentially the same value very quickly and its silly for us to be racing to post solutions.
I actually put together a program last night that keeps a table of all the best sequences I have found for k0 <= 10000, as well as all smaller records that can be derived as subsequences. As I'm working on a particular k0, it checks each new sequence it generates (even if the diameter did not improve) to see if it contains a subsequence that beats the best bound I have for a smaller k0. So for example I already have sequences with k,d values
5452,51520
5451,51510
5450,51492
5449,51482
5448,51472
5447,51462
5446,51456
…
2,2
1,0
that were found as a by-product of searching for better solutions for k0=5453. I expect many of these bounds can be improved by focusing on them specifically, and I'm actually working now on a program that iterates through all the records trying to improve each one, generating a cascade of improvements for smaller k0's as it goes. The nice thing is that when you make plateau moves at a particular k0, you will often hit a new internal combination that produces a record for a smaller k0.
Now rather than having people rush to make a "land grab" to stake out claims to the best bounds for particular k0's, what I think it would be more productive is to set up an automatically updated web page with a complete list of record H(k) values for all k up to, say, 10000 (and maybe even a record of all known distinct solutions at the same value). Anyone who wants to contribute a new solution for a particular k0 can do so. The program will then automatically update all the smaller records that it can based on sub-sequences of the contributed sequence.
BTW, I agree with you that there are still some "hard" k0's where we can't quite get down to the smallest diameter. I actually have some ideas on how to address this: I was able to find an optimal sequence for k0=200, by optimizing the initial set of sieving residues at small primes in a different way (i.e. they don't correspond to a shifted Schinzel sieve for any small shift value). And I bet the same thing will work for 672. But I haven't had time to focus on it because I've been distracted by all the ups and downs in k0.
@andrew: seems that we have the same thought.
I don’t know how to generate an automatically updated webpage for this. So I have started a wiki page as a template:
http://michaelnielsen.org/polymath1/index.php?title=Benchmarks_of_small_admissible_tuples
Please have a look to see if it is a suitable starting point. Feel free to modify it.
@xfxie: regarding #302 (which I only just noticed now, I need to remember to refresh my browser before I post), here are the sequences I currently have for 5446 thru 5451 (see #298 for 5442)
http://math.mit.edu/~drew/admissible_5451_51510.txt
http://math.mit.edu/~drew/admissible_5450_51492.txt
http://math.mit.edu/~drew/admissible_5449_51482.txt
http://math.mit.edu/~drew/admissible_5448_51472.txt
http://math.mit.edu/~drew/admissible_5447_51462.txt
http://math.mit.edu/~drew/admissible_5446_51456.txt
All these were found yesterday while the program was hammering on 5453.
@Andrew: It sounds like a good idea to do things more systematically, especially now that is small enough that it becomes computationally feasible to do a large number of values of
is small enough that it becomes computationally feasible to do a large number of values of  at once. How difficult would it be to actually set up an automatically updating web page though that can accept submissions? Presumably it would be easier to set this up on one’s own web page rather than through the wiki.
at once. How difficult would it be to actually set up an automatically updating web page though that can accept submissions? Presumably it would be easier to set this up on one’s own web page rather than through the wiki.
Andrew, your procedure sounds very familiar to what was done in 2006. I have archived all found patterns, but providing them would be rather impossible for me, as there is 393 gig of data. If there are specific diameters or K values let me know.
xfies for your table I possibly could convert one tuple of each width to your numerical coding system.
@Terence: I should be able to set this up — I can host it off my MIT web site. To get something up quickly (e.g. today or tomorrow) I may need to have the submission process happen via e-mail initially (which can then be handled automatically), but I should be able to put something form-based together eventually (e.g. next week).
@Thomas: Storing all the patterns may be hopeless, but it might be possible to store a hash value for each pattern that would at least give us a sense of how many distinct minimal solutions have been found for a given k (per your observation on Tao’s blog, when this number is large, it may be a sign that the bound is a good target for improvement). I’ll need to think about this, but initially it might make sense to just keep one pattern per k.
Once I have the table more fully populated with good bounds I will have a better sense of where there are regions in your tables where our algorithms are having trouble finding a pattern that matches your bounds.
@Andrew – I’ve been told good things about Google forms by someone who uses it (I haven’t used it myself):
https://support.google.com/drive/answer/87809?hl=en
This should enable easy manual form-based entry of the data, or else automated entry (through http POST requests). All the data then goes into a Google spreadsheet. May be worth looking into.
@Michael: Thanks, I’ll take a look. I’m certainly no expert at this sort of thing, but I do now a few people who are — I’ll ask around.
One compromise option would be a shared Google Docs spreadsheet, as one could semi-automatically add large amounts of data by downloading the spreadsheet, editing it, and importing it back. I made a quick prototype at https://docs.google.com/spreadsheet/ccc?key=0As_y1RgcBvwxdGNsRTlRTlI2MENXdVZlc0JLXy0tWnc#gid=0 with a tab for world records (both upper and lower) and a tab for base tuples (ones that are not obtained by truncation from other tuples). (Vit Tucek had an earlier version of the latter tab at https://docs.google.com/spreadsheet/ccc?key=0Ao3urQ79oleSdEZhRS00X1FLQjM3UlJTZFRqd19ySGc#gid=0 , maybe they can be combined.) So maybe we can submit records primarily to the spreadsheet and only report highlights on the blog and wiki?
Ah, I posted without seeing the last few comments. If a more automated system is easy to set up then that would be superior to the Google Docs proposal.
@Terry @Andrew Looks like Google spreadsheets has an API:
https://developers.google.com/google-apps/spreadsheets/
So it should be possible to automate entries that way, as an alternative to Google forms.
Seems there are better solutions (Google products, automated submission forms). I will temperately submit solutions to the wiki page, and move them to the new submission system when it is available.
@Thomas: It would be quite interesting to see your tuples online (one tuple for each instance should be fine).
For your consumption, uploading one of pattern of each minimal diameter tuple for each k 2-4507 (from the 2009 data).
A directory tree of 100 k-values per page at http://www.opertech.com/primes/webdata has been uploaded.
Unlike the w2329 (k342) compressed files I provided with the “1..11” patterns, I was able to decompress the data and rewrite the data to match your ‘txt’ files. All patterns are ‘0’ based, eg. the minimal diameter tuple for k0=342 would be found in directory k2-1000, then k300-399, then would be the file ‘k342_2328.txt’.
Was able to upload thru k0=2400, 3000-3099, 4000-4099 until my limit was reached. Will upload more as space opens. Any specific k0s wanted let me know.
@Thomas: thanks!
@Thomas: Excellent! I think the value of may drop soon (as in within the next 48 hours) to your threshold of 4507 or below, so we’ll have an immediate baseline value of H and there won’t be the mad scramble to get 15 minutes of fame any more. :)
may drop soon (as in within the next 48 hours) to your threshold of 4507 or below, so we’ll have an immediate baseline value of H and there won’t be the mad scramble to get 15 minutes of fame any more. :)
@Scott: perhaps once we have a page up for the world records that can accept submissions on an automated basis, it might be a good time to roll over the thread and advertise the new page?
@Terence: I’ve got some people working on putting together an automated web-based submission/query system now. They claim they can have something rudimentary working by tomorrow (of course this is software we are talking about, so we’ll see…)
@Thomas: Is it OK with you if I populate the initial database using a merge of your sequences and mine (I have a sequence for every k up to 10,000, but most of them are not very good), plus the sequences that have been posted on this thread (all appropriately attributed of course). In some cases we have better H bounds than you, but in most cases your sequences will be the benchmark.
@Andrew: That is why the work was done, to be used. The data served our purpose with the k(w)-pi(w) project. Then Goldston et.al. was able to use some of the data in their ‘Primes in Tuples’ paper. This project is an added bonus.
Yes, I’ll roll over the page then! Sorry I’ve let it run so long without re-summarizing.
scott
Too early to start claiming anything, but here’s a rough calculation by Terry which indicates k_0 might be soon on the order of 1512.
http://terrytao.wordpress.com/2013/06/12/estimation-of-the-type-i-and-type-ii-sums/#comment-235476
That will lead to around 12436.
Actually, Engelsma already gave a better bound. If k0 indeed drops to that scale, there is almost no usage to do further computation.
For k from 1450 to 1550 (inclusive) I am able to improve Engelsma’s
bounds in the following 16 cases:
http://math.mit.edu:/~drew/admissible_1474_12072.txt (vs 12078)
http://math.mit.edu:/~drew/admissible_1476_12086.txt (vs 12096)
http://math.mit.edu:/~drew/admissible_1477_12102.txt (vs 12102)
http://math.mit.edu:/~drew/admissible_1494_12272.txt (vs 12274)
http://math.mit.edu:/~drew/admissible_1500_12320.txt (vs 12324)
http://math.mit.edu:/~drew/admissible_1503_12348.txt (vs 12356)
http://math.mit.edu:/~drew/admissible_1504_12356.txt (vs 12360)
http://math.mit.edu:/~drew/admissible_1505_12362.txt (vs 12366)
http://math.mit.edu:/~drew/admissible_1506_12368.txt (vs 12378)
http://math.mit.edu:/~drew/admissible_1528_12570.txt (vs 12576)
http://math.mit.edu:/~drew/admissible_1533_12620.txt (vs 12622)
http://math.mit.edu:/~drew/admissible_1534_12630.txt (vs 12632)
http://math.mit.edu:/~drew/admissible_1544_12714.txt (vs 12714)
http://math.mit.edu:/~drew/admissible_1545_12724.txt (vs 12726)
http://math.mit.edu:/~drew/admissible_1546_12732.txt (vs 12738)
http://math.mit.edu:/~drew/admissible_1548_12746.txt (vs 12750)
In the other 85 cases, I am able to match his bounds exactly. This was achieved with a new “bulk processing” approach. The algorithm use essentially the same ideas that have been developed in this thread (at its core it still uses the greedy-greedy algorithm followed by local optimizations), but it looks for solutions for many k’s simultaneously rather than fixing on a single value of k0.
It’s worth noting that so far I have not made use of any of the sequences that Thomas was kind enough to post. These results were achieved entirely by methods developed as part of this polymath project.
@xfxie: I expect the tuples in the area given can be improved – see below. But I am somewhat sad that the k-value might be lowered to this level. Now the higher values will be ignored while they are still of great value to k()-pi() work. (eg. the k3405 tuples found by this polymath project are fantastic, they may even cause a relapse of my ktuple addiction as I want to see the improvement of the k()-pi() graph.)
@Andrew: Use them, embedded tuples are a core element in searches and excellent seeds. Not using them is like doing the a sieve of eratosthenes but not using ’17’ because someone else did. In an earlier post, you mentioned a pattern cascading, similar events happened here – was part of the fun/excitement. Most tuples in the above area have 2000+ variations archived. Let me know if you want any particular diameter for ‘seeding’.
*****
The following was posted on http://terrytao.wordpress.com/2013/06/14/estimation-of-the-type-iii-sums/#comment-234742 , but is more relevant for this discussion.
The chart at http://www.opertech.com/primes/varcount.bmp shows the number of variations that are archived for each width.
There are 3 colors shown
green — variations found from true exhaustive search.
blue — variations found using targeted search routines – close to densest
red — variations generated from smaller tuples – just best found
‘Exhaustive search’ was true pruning exhaustive search.
‘Targeted search’ was recursive searching of a specific width
‘Generated’ was creating tuples using existing patterns (mostly smaller)
This was done due to the evidence that most tuples had smaller tuples embedded.
The tuples in the red zone were investigated mainly to see if k(w) stayed above pi(w) or oscillated around pi(w).
See http://www.opertech.com/primes/trophy.bmp Amazingly, k(w) is concave upward, and every improvement causes it to rise faster.
(current work implies that there is no inflection point, showing ever growing localized order amid the global chaos of the primes)
Also, the improvements of k()-pi() were not evenly scattered as w grew, but clustered (the series of red and blue dots) Whenever a series of red dots does not have a corresponding series of blue dots, those tuple widths should be able to be easily improved.
The headings of the table at http://www.opertech.com/primes/summary.txt are:
1st col — w width of interval, number of consecutive integers
2nd col — k [has value if first occurrence of a k]
3rd col — k number of admissible elements
4th col — k(w) – pi(w) [has value if first occurrence of k()-pi()]
5th col — k(w) – pi(w) over pack/under pack quantity relative to prime count
6th col — number of variations currently archived
The number of variations gives a clue if a tuple can be improved. When tuples in the red-zone have 1000s of variations, that width should be able to be improved. When the searching was active, if an improved tuple was found, it was tested to generate 1000 variations.
One more improvement:
http://math.mit.edu:/~drew/admissible_1539_12672.txt (vs 12674)
Well, it still seems much easier to improve Engelsma’s bounds in larger k0 values.
For example, in [3001-3050], 45 of 50 instances (except for 3023, 3031, 3034, 3038, 3050) can be improved in short computation times.
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3001_26614_1618.txt 26630 -16
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3002_26630_1238.txt 26634 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3003_26634_1234.txt 26642 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3004_26642_1226.txt 26654 -12
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3005_26660_1514.txt 26666 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3006_26666_1202.txt 26670 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3007_26670_1198.txt 26682 -12
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3008_26688_1486.txt 26694 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3009_26696_1478.txt 26706 -10
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3010_26700_1466.txt 26720 -20
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3011_26708_1466.txt 26730 -22
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3012_26720_1454.txt 26736 -16
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3013_26736_1438.txt 26742 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3014_26742_1126.txt 26754 -12
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3015_26762_1466.txt 26770 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3016_26766_1466.txt 26784 -18
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3017_26778_1388.txt 26792 -14
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3018_26784_1382.txt 26802 -18
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3019_26804_1514.txt 26808 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3020_26814_1514.txt 26820 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3021_26826_1492.txt 26828 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3022_26832_1486.txt 26844 -12
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3023_26848_1318.txt 26848 0
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3024_26850_1468.txt 26856 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3025_26862_1466.txt 26874 -12
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3026_26874_1454.txt 26884 -10
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3027_26884_1282.txt 26892 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3028_26888_1466.txt 26904 -16
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3029_26904_1262.txt 26912 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3030_26912_1262.txt 26928 -16
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3031_26932_1234.txt 26932 0
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3032_26932_1234.txt 26940 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3033_26940_1234.txt 26948 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3034_26960_1214.txt 26960 0
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3035_26970_1466.txt 26968 2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3036_26968_1198.txt 26976 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3037_26976_1198.txt 26988 -12
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3038_27000_1174.txt 27000 0
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3039_27050_3194.txt 27018 32
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3040_27020_1466.txt 27028 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3041_27030_1486.txt 27036 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3042_27042_1174.txt 27048 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3043_27048_1126.txt 27058 -10
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3044_27062_1454.txt 27066 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3045_27078_1438.txt 27080 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3046_27090_1226.txt 27098 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3047_27102_1114.txt 27108 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3048_27114_1202.txt 27118 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3049_27118_1198.txt 27130 -12
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_3050_27142_1174.txt 27142 0
For k0 in [1350, 1399], I only achieved improvements on 8 of 50 instances. Maybe need to run more time to have more.
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1361_11020_892.txt 11022 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1362_11026_886.txt 11034 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1365_11052_692.txt 11062 -10
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1366_11064_692.txt 11066 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1367_11066_692.txt 11070 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1373_11134_628.txt 11138 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1374_11140_622.txt 11146 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1392_11330_692.txt 11340 -10
Further improvements
http://math.mit.edu:/~drew/admissible_1472_12056.txt (vs 12060)
http://math.mit.edu:/~drew/admissible_1492_12254.txt (vs 12258)
http://math.mit.edu:/~drew/admissible_1508_12392.txt (vs 12396)
http://math.mit.edu:/~drew/admissible_1509_12398.txt (vs 12404)
http://math.mit.edu:/~drew/admissible_1510_12408.txt (vs 12410)
And I notice a typo in #327, the Engelsma bound for 1545 is 12726.
Er, I meant that the Engeslma bound for 1544 is 12716, not 12714 as written in #327.
For k0 in [1001, 1099], only achieved improvements on 9 of 99 instances.
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1030_8070_508.txt 8074 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1031_8076_502.txt 8088 -12
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1032_8092_502.txt 8098 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1033_8100_478.txt 8106 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1035_8118_454.txt 8124 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1040_8166_446.txt 8172 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1065_8408_626.txt 8410 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1067_8416_622.txt 8424 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1079_8526_508.txt 8532 -6
For k0 in [1500, 1599], only achieved improvements on 16 out of 100 instances.
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1506_12368_1076.txt 12378 -10
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1503_12348_-13424.txt 12356 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1546_12732_692.txt 12738 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1500_12320_1124.txt 12324 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1504_12356_1082.txt 12360 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1505_12362_1076.txt 12366 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1518_12486_-13868.txt 12490 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1549_12764_674.txt 12768 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1553_12806_1466.txt 12810 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1554_12818_1454.txt 12822 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1567_12944_-13852.txt 12948 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1510_12408_1076.txt 12410 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1525_12544_-13436.txt 12546 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1534_12630_758.txt 12632 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1539_12672_716.txt 12674 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1545_12724_694.txt 12726 -2
For k0 in [1100, 1199], achieved improvements on 23 out of 100 instances.
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1189_9500_1514.txt 9514 -14
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1194_9548_1514.txt 9560 -12
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1190_9512_1502.txt 9522 -10
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1127_8958_956.txt 8966 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1141_9076_838.txt 9084 -8
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1150_9150_764.txt 9156 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1151_9156_758.txt 9162 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1168_9324_914.txt 9330 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1169_9330_908.txt 9336 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1173_9370_862.txt 9376 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1183_9452_1514.txt 9458 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1188_9498_1516.txt 9504 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1192_9534_1514.txt 9540 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1193_9540_1514.txt 9546 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1195_9560_1502.txt 9566 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1199_9596_1466.txt 9602 -6
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1130_8986_922.txt 8990 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1191_9528_1486.txt 9532 -4
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1165_9300_614.txt 9302 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1170_9340_892.txt 9342 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1174_9384_1514.txt 9386 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1178_9418_838.txt 9420 -2
http://www.cs.cmu.edu/~xfxie/project/admissible/admissible_1181_9444_1514.txt 9446 -2
OK, now I’m sorry I didn’t get a submission site up yesterday. But in any case, top stop the spamming of this thread, here is a list of my current records up to 4507
http://math.mit.edu/~drew/records.txt
@Andrew, many of the links in your records.txt seem to be broken.
@Scott: oops, try again, they should work now
@Scott: here is a better version that goes to 5000
http://math.mit.edu/~drew/records2.txt
Here’s a new records for 1468, beating the Engelsma bound by 2:
http://math.mit.edu/~drew/admissible_1468_12020.txt
Here’s another improvement, a bit outside the range of interest, but just in case we need to retreat slightly:
http://math.mit.edu/~drew/admissible_1485_12180.txt
Seems the game is no longer public.
I will spam only last time for the range [1200, 1299], only 7 solutions were found better than Engelsma’s bounds (only the last one is better than the element in records2.txt):
admissible_1200_9608_1454.txt 9612
admissible_1239_9932_1082.txt 9938
admissible_1240_9938_1076.txt 9948
admissible_1243_9972_1042.txt 9974
admissible_1251_10050_838.txt 10052
admissible_1255_10094_794.txt 10098
admissible_1291_10396_1108.txt 10398
Fortunately, this spam is not too long.
Here is an updated list of sequences for k from 342 to 5000, it contains 580 improvements over records2.txt
http://math.mit.edu/~drew/records3.txt
Just an update on the status of the k-tuple submission server. The client side is working, with a simple form for submitting sequences (which will then be verified for admissibility), and for browsing existing sequences. But the server side is still coming together (the department just relocated all our servers, which is slowing things down a bit). It may be the weekend before we get it online, but it is coming.
@Thomas: I agree completely that an up-to-date k-tuple database is a useful resource above and beyond the prime gaps project and I am committed to making this happen. I’m also frankly amazed that our greedy optimization algorithms are able to do so well, I would not have expected this a priori . In fact if you hadn’t done your exhaustive search, I’m not sure I would believe that, say, the sequence for 342 listed in the wiki is actually the best possible — it only takes a matter of a few seconds to find it (!).
While initially the tuple database will only store one sequence per k, I have been thinking about the idea of categorizing solutions according to the sieved residues modulo small primes, e.g. up to the square-root of the diameter (or maybe a bit smaller). It seems that most of the variations tend to occur by swapping residues at larger primes, but at the small primes it seems that there are only a few patterns that tend to arise for a given k. What do you think about this?
I just realized that we now have a sequence for k0=672 of diameter 4998, matching Engelsma’s bound. I was never able to find this by searching specifically for k=672, but in the process of populating the database, it popped out as a subsequence of a sequence for a larger k. So there are no longer any asterixes on the table in the wiki.
Another table update with 405 improvements:
http://math.mit.edu/~drew/records4.txt
@Andrew: As you go farther into this project you will find that retaining data is very important. For the information to be useful to all parties, the data must be stored by width not by k. By having k=F(w) you can simply extract wmin=F(k) but the convex is not possible. The database here is binary, I was able to store every pattern found as a bit pattern. There are multiple benefits (other than size) from doing this, first as you are now finding out, dense tuples tend to embed, with the bit pattern I could easily and efficiently overly and test patterns using mere logic functions. Second, displaying tuple patterns graphically can give you insight on what to look for, and how to ‘tweak’ an algorithm for better searches. But like I said earlier, the most important thing is to preserve until invalid.
@Andrew: Just re-read the post, I am not converted to using diameter for tuples yet. [In a world were pi are square, I guess tuples can be round]
And the link in prev post does not work.
@Thomas: I agree 100% about saving data, which is why I want to get this thing set up properly on a hosted server with plenty of fault-tolerant storage rather than copying files around on my development machine (initially I was being paranoid and working in Dropbox, but the network traffic it was generating became unmanageable).
You make a good point about storing tuples by width. I agree that this gives more information (although if one knows the exact value of H(k) for all k, one can compute the exact value of any F(w)).
In terms of storing patterns I’m not still sure how feasible this is, it requires further thought. In the short term (i.e. this weekend) I just want to get something up and running that maintains a list of k-tuples that achive the best known bound on H(k).
The good news is that, at least up to this point, all our results are fairly easy to replicate when k is of moderate size (say k < 10000). This is one thing I find reassuring about our randomized methods, they thus far aren't don't depend on getting spectacularly lucky. xfxie and I generally have no trouble replicating each other's results within a short period of time, especially if we know the sieved residues at small primes (this amounts to knowing what happened in the first phase of the greedy-greedy algorithm, the shift offset being used), even though we will almost never find the exact same tuple. But as the bounds get better and more computation time is spent on the problem, I suspect this will become less true.
@Thomas: The link in #349 should work now, but I realized that a bunch of updates inadvertently got left out, so here is a new link with another 405 updates.
http://math.mit.edu/~drew/records5.txt
So far I have been able to improve your bounds for 1040 values of k in the range 343 to 4507, the smallest of which is 785. There is still a fair amount of optimization that can be done at the higher end, so I expect this number will go up.
For the range 1400-1470 of potential interest, I have better bounds at the following k: 1415,1417,1423,1428-29,1437-39,1441-43, 1468. The sequences can all be found at the link above.
Depending on family, this weekend I hope to load up the k()-pi() program and regenerate the graph using the current advances.
Also, check if I can port the generate program to today’s PC and operating system — not much faith in that being easy.
New version with 1384 improvements
http://math.mit.edu/~drew/records6.txt
If all goes well with getting the submission server up today, this will be the last such post.
One more update with 195 improvements
http://math.mit.edu/~drew/records7.txt
This version improves Engelsma’s bounds at 1557 values of k, including 29 values in the range [1400,1500] (but no improvement at 1466 or 1467).
It also includes a new record at k= 4000, with a diameter of 36,610. I have updated the corresponding entry in the table on the Wiki.
After some unanticipated delays due to a combination of server relocations and vacations, a test version of the submission server is now online at
http://math.mit.edu/~drew/ktuple/primegap.html
This is a java script client that is accessing a mongoDB backend that holds the metadata. The k-tuples themselves are currently stored as text files that I hope to eventually migrate to Dropbox so that anyone can setup a replicated copy if they want (but this requires a little more fiddling with the Dropbox api’s than I have time for now).
The URL above is temporary, it will eventually move to its own account on the MIT math server.
In order to exercise the server, I have populated a test database with k-tuples for k from 2 to 500 that are intentionally not the best possible (I just used the first k primes greater than k). People are encouraged to experiment with submitting better sequences. The client is very flexible on the format, anything that is ascii text with numbers delimited by something (spaces, commas, linebreaks, whatever) should work, and it will just ignore any extra brackets, braces, etc…
In addition to a list of the current records for each k, you will also see a submission log that shows submission I have made for k=342 corresponding to the various cases listed in the table on the wiki (Zhang sieve, Hensley-Richards, etc…).
I am currently putting together a complete database of the best k-tuples we have form k=2 to 5,000, starting from a merge of Engelsma’s tables and mine (the latest of which is records9.txt), and then adding sequences that have been posted on this thread (with precedence to those posted first). I hope to have this online later today. Aside from accepting submissions it will also be useful to those monitoring the rapid progress on reducing k0 who want to browse a list of the most current H(k) bounds in a given range. I also plan to add entries for the specific k’s that appear in the table on the wiki. Eventually I’d like to make it comprehensive up to 10000, but 5000 will have to do for now.
There are several features I want to add, only one of which is likely to get done before I leave for a 3-week trip to Europe next week: I want to have the back end automatically check for any records that it can easily derive from a given sequence (e.g. subsequences) and if it finds any derived records it will also post them on behalf of the submitter of the original sequence.
So please take a look at it and play with it, and let me know of any problems and/or suggested improvements. The sooner the better, since I’d like to get the real thing up and accepting submissions by the end of they day.
Excellent, someone already found a bug in the test submission server :). It’s now fixed. I also realized that for small k taking the first k primes greater than k is often optimal, so I made the sequences for k < 10 in the test data easier to beat by replacing them with 2 time each of the first k primes greater than k.
Is it really necessary to ask for the diameter in the submission form? It seems an unnecessary step of copying and pasting, since it’s going to check this anyway.
Also, why require that the uploaded file has a name ending in “.txt”?
On Tue, Jun 25, 2013 at 10:30 AM, Secret Blogging Seminar
@scott: The original plan was to accept both lower and upper bounds, and in the former case the server can’t easily validate the claimed bound. But in the case of upper bounds (which is all it handles at the moment), I agree there is no reason to ask for the diameter. I’ll see if I can get this changed, and also address your second point. Thanks!
@Andrew: The “data link” for the best 6-tuple and the best 10-tuple does not work.
@Andrew: This looks great! One minor thing: Are previous records for a given k still stored somewhere? It might be nice to be able to click on a value of k and get a list of all past world records as well as the current one.
I was going to suggest that new tuples could also be entered in directly via a text box, but I guess this would only be practical for very small tuples for which we already know all the optimal tuples anyway (and presumably any larger tuple that is found can be trivially stored into a text file in any event).
@Hannes: fixed, thanks.
@Scott: I’ve changed it so that you are not asked to enter either k or the diameter, the server fills these in when it parses the file. This means your submission may have a blank k and bound field for a few seconds (I may move this client side later). And it doesn’t care what the file extension is (but the server expects ascii text regardless).
@Terry: All accepted submissions (with the associated tuples) will be preserved indefinitely, so we can certainly make the history viewable.
The easiest thing to do might be to an option to filter the submission queue by k. I also thought about doing data entry/display of individual tuples in the client, but it gets unwieldly very quickly as k grows. I do plan to add the ability to extract additional information from the tuples, e.g. a list of sieved residue classes.
I will be pushing a new version of the client with the fixes in #362 and some cosmetic clean-up in a little bit. It’s still a bit rough around the edges at the moment.
The client has been updated (you just need to refresh your browser). @Scott: you should now be able to just enter your name and upload a file (with any extension) to submit a sequence (along with an optional comment). Please let me know if you have any problems.
@Andrew: If I ask it to list the records for k from 90 to 100 it shows for k from 9 to 100.
@Hannes: Thanks. My guess is that it is filling the display with records from 9-100 in between the time you type the 9 and the 0 in 90. I can put in a delay so that it waits until you seem to be done typing (say 500 ms) before updating the screen (or I could put in a “submit query” button, but this seems like overkill). In any case, it should eventually (within a second or two) display just the 90-100 that you asked for, is that not happening?
@Andrew: I tried again and it worked as intended! However, trying (reloading the page and then typing 90 in the “from-field”) a few times more brought back the bad behavior. It appears it very briefly shows 90-100 and then changes to 9-100. After that it does not switch to the correct range 90-100.
Perhaps this is a problem on my side.
@Hannes: Hmm, what browser/OS are you using? In any case, I’ve put in some changes to make the auto-update behavior less aggressive and hopefully less confusing. These will be in the next version of the client that I’ll push out later today.
@Andrew: Firefox 21.0/Windows 7 Professional. I can try it on another computer later today.
@Hannes: I think I know what the issue is. With java script’s asynchronous event-driven execution model it is possible for the responses to the queries for records 9-100 and 90-100 to get displayed out of sequence, especially since the first takes longer than the second (I’m not really a java-script programmer, but this seems entirely plausible to me). A small timing tweak should make this much less likely to happen. In any case it’s probably not platform specific, other than being more likely to happen on a slower machine.
@Andrew: Tried a second computer now (running Firefox 19.0). Same error.
It appears to work well when I type slowly (so that the list is updated after each entered digit). But when I type 90 fast it first displays the correct list, then shows 9-100, and then stays put.
@Hannes: I posted a new version of the client that should address the issue. It no longer has a min and max, just a min with max set to min+100. It also waits until it thinks you are done typing before sending a query to the server (pressing enter will force it to send the query immediately). Let me know if you notice any further usability issues.
In the meantime, I am close to having an integerated database of best known tuples for all k up to 5000 ready to release. But I have some other things I need to get to get done today and I wan’t to sanity check it a bit more before posting it so it may be tonight or tomorrow before that happens.
I remember once seeing the same issue (on a fast computer!) In the callback function, put in a check to see if that textbox still contains the same value. If not, just stop.
No more problems on my computer (with this particular issue at least).
Typo: interset
The integrated tuples database is now online!
I have merged the data from Engelsma’s tables, my tables, and the sequences that xfxie has posted here, for k up to 5000. Where there were duplicates, I credited the first person to post the sequence (or Engelsma, if it was from his tables).
The submission server is not yet active, but tomorrow morning it will start accepting new submissions. In the mean time the database is available for browsing, which may be helpful to those monitoring the rapid-fire improvements to k0.
The (now permanent) link is:
http://math.mit.edu/~primegaps/
@xfxie: I went through your posts on this blog and wound up posting a total of 93 of your sequences. I think I got them all, but you might want to double check just to be sure (if you find any I missed, please let me know).
@Scott: I implemented your suggestion, along with a couple of other tweaks that improved the performance and behavior of the client.
@Andrew : great news! I am planning a new post on the blog to try to give a high level summary of the state of the polymath8 project (most of my recent posts have been focused on technicalities), and will definitely advertise this new site once the submissions are back online.
One feature that might be nice to have in future (but it is not urgent) is to be able to view the table of H(k) bounds in plaintext form for longer arrays of k than 100, so that the data can be easily converted to other formats.
Eventually it would be nice to also record lower bounds, but I certainly see the problem that there is no easy way to certify in an automated fashion that a claimed lower bound is correct, in contrast to an upper bound that can be certified by submitting a tuple. Given that there has been fairly little activity on lower bounds thus far, we can continue recording them by ad hoc means for now, with people compiling separate tables of lower bounds (or working with specific benchmarks, e.g. k_0 = 1000) and not merging them into the web site, at least not for now.
The submission server is now online and ready to accept new tuples.
I encourage everyone to help improve the database!
While the recent progress on reducing k0 may be leading us to a region where further improvement in H(k0) upper bounds becomes very difficult (or even impossible), I hope this won’t discourage people from submitting new bounds. This information is valuable for many other purposes, e.g. the question of pi(x+y)-pi(x) versus pi(y), which is what motivated Engelsma’s original computations. I should also emphasize that it is definitely possible to improve Engelsma’s bounds even for k0 below 1000 — I have done so in 26 cases so far, the smallest of which is for k=785. And for larger values of k there is still a lot of room for improvement. Between the two of us, xfxie and I have managed to improve on Engelsma’s original bounds in 1588 cases, more than a third of the 4506 values in his tables, and I’m sure there are many more improvements still to be found (in fact I just posted one to the server a few minutes ago, for k=2588, which improved a bound that was already an improvement over Engelsma’s tables).
@Terry: it should not be hard to add an option to download a text file with all the current upper bounds, I’ll see if I can put that in today or tomorrow. Regarding lower bounds, one thought I did have is that computing the best partition lower bound on H(k) for all k <= 5000 via dynamic programming, as described by Avishay, would not be hard, and it would set a pretty good baseline, especially for small values of k (I believe that for 343 <= k <= 1000 partitioning gives the best lower bounds we know, but Avishay can correct me if I am wrong here).
@Andrew: You are correct. The best lower bounds up to k=1000 are derived via dynamic programming and Englesma exact bounds for k1400 approximately, the inclusion-exculsion method with initial sieve of primes up to 19 gives better lower bounds.
It is reasonable that an improved lower bounds for some specific k>342, will improve lower bounds for k’s larger than it.
I’m attaching a list of lower bound for k<=5000. The list was generated using Engelsma's values for k<=342 and the method of partitioning (dynamic programming).
https://sites.google.com/site/avishaytal/files/lower_bounds_englesma_tables.txt
@Andrew: LOOKS GREAT — needed interest like this in 2005.
I have been making manual changes to the k()-pi() graph, but I think I’ll wait for the file that Terence asked for.
So far, here are the graphical improvements: http://www.opertech.com/primes/polymath/9-27temppolymath.JPG
— on the graph x-axis is diameter, y-axis is k(diameter)-pi(diameter)
The black dots are using the current values of k() [first occurrence), while the gray line represents kb(w) [bounded for each diameter]
Shows some real jagged moves.
For the record hunting, the graph may help to show areas
eg. the flat line from diameter about 19500 to 23000, and namely the gray section around 21400 should pop thru, and provide a major cascade of record k0 values.
The area above 34000 I totally expect you can grow most of those at least 5 and possibly more. (You are already improving them nicely.)
Was in the process of adding 1024 variations to each width, as seen by the red line running up to about 20000.
As for records, I believe you should be able to improve the k0 values for that entire range. These k0s are ‘best’ found during generation. As the gray line ran down those widths received less attention, but your search will still find better k0s, for instance the ks around 24000, dive 10 counts below the current kb()-pi() value, so 24000 area was ignored. Any true searching was done when kb()-pi() was within 1 count of the existing value, the rest was ‘generate’.
Still amazing to me, in a tuple width as small as about 40000 you can pack up to 150 more primes than pi(40000). More amazing is it appears to run away from pi() faster than c*log().
Another aid in the record hunting might be the variation counts, I’ll try to explain the purpose of it. http://www.opertech.com/primes/varcount.bmp
Given a core residue set for an admissible tuple, a ‘generate’ program was written to just try and reshuffle it. When a set easily recreates patterns those core residue sets are probably not going to make any improvements. But by doing this the core residue sets that were ‘tough’ popped out of the data, and most of the time that core residue set could be applied to neighboring widths. Was a time consumer, but valuable in learning the structure of the very erratic Kb()-pi() function.
And speaking of ‘tough’ patterns, it’s not a k0 record contender, but break the diameter 5238-698 tuple, was my problem child tuple since 2005, and to this day have not been able to improve it. (believe 200000+ patterns of 698 have been interrogated) Your method is very different as your searching for k, so you very well could bust it.
Whenever an idea came up to ‘tweak’ the recursive search program, 5238 was tested first.
And I repeat, nice work on the Tuple Collector program, you should see nice gains as interest grows.
Have a good holiday all.
Thanks for the explanation by Andrew and Thomas — I get more sense about potential usages of the database. Maybe it is helpful to summarize some possible usages to a FAQ/introduction page, which might help some non-math guys with more motivation to contribute for the database.
A minor suggestion: It might be useful to have a short name (which is easy to remember) for the database.
BTW: It might be nice if the website could accept submission in a tar/zip file (a limit on the file size might be set, if necessarily).
@Avishay: Last night I wrote a simple program to compute partition-based lower bounds for k = 4248? And perhaps post a file with your upper bounds on M_d for d <= 34068? Thanks!
@Thomas: Thanks for the information and the charts, very interesting. I just posted some tuples that are just below the diameter 19500-23000 region you highlighted. I’m setting up a run now to focus on that area in particular. Also, as requested, I have added an option to download a current list of all the upper bounds in the database, look for the link in the text at the top (it is automatically updated as new records are posted, so it should stay current to within the last few seconds or so).
@xfxie: Adding a bulk submission option is a great idea but it might take me a bit of time to implement and I don’t think I can get it done before I head to Europe tomorrow morning. However, if you e-mail me a zip file containing a bunch of admissible*.txt files, I can post them all using the manual batch submission script I originally used to initialize the tables (however it would be helpful if you only include files that you believe are new records rather than sending me everything). Also, I do plan to eventually put tuples for selected larger values of k into the database (e.g. 34429). I’d actually like to post all the sequences we have listed in the table on the wiki, progressing the first k primes past k all the way to the best known sequence, so that people can see the progression in the submission history (I plan to add an option to filter submission by k). In the meantime if you find improvements to any of the larger sequences in the wiki table, please update them there.
@Avishay: I see my post #379 got truncated for some reason. I meant to say that I get the same values as you at most k, but there are a few dozen places where we disagree and I would like to understand why. The first place where we disagree is at k=629 where you get 4248 versus my 4246.
Given that Engelsma’s exhaustive search was done about 4 years ago, and that now there seems to be more interest, is it possible to do a larger exhaustive search?
With the same method, but around 10(?) times more computer power, this might help reach the latest projections for k0, which are beyond 342 but below 1000… I don’t know the complexity of Engelsma’s algorithm.
Do we know how many CPU hours went into Engelsma’s search?
Yeah !! have the recursive search able to target a specific k0 and format output to that of the database. Took a few rejections before I realized I didn’t fully decompress the file. Have some more playing with the recursive search program as this run was ‘hand’ fed data.
@Scott: At the moment I have dragged the project boxes out, and will be checking the feasibility of starting up the exhaustive again with today’s tech. Problem will be that the assembly program was ‘tuned’ to run on the chip I had in that computer. Goal was conserve clock cycles. Ballpark of CPU time is it checked 20 widths (2311 thru 2331) in 7 months of continuous run. We will gain from tech, but lose 8x that from the addition of a branch after 2331. Need some time to go over things. Other way may be to use a higher level program and distribute it.
@andrew: It is great to have that automatically generated ubounds.txt file. We can use them to automatically filter inferior solutions before submission.
After checking the old running directory, there are indeed two improvements for the large sequences, I have updated them in the wiki table.
Do you have a sense of what the speedup was from going to assembler on a specific chip? Assembler and/or GPU programming is above my pay grade, but I could help organize CPU time.
@Thomas: your new record at 2150 was awesome! It gave me a new set of core residues to feed my program and I was able to improve the bounds at a dozen neighboring k’s. Interestingly, I was able to get better sequences than you did at nearly all the neighbors I think this is an advantage of using a variety of different algorithms — the optimized greedy-greedy algorithm does very well if it has a good start of core residues at small primes, but it has a hard time moving away from a local minimum at a particular core set.
Can you try some other values of k? (e.g. some smaller ones?).
@Scott: Don’t know/remember what the specific gain was, but it was 1000s of times faster than compiled C. Used C to prep/test concepts during development. Just need some time after holiday to go through everything again.
@Andrew: Will do. You hit on one of the problems with the search. Kind of like the cross pollination of a field. One residue set can easily become dominant, aka. the reason for the ‘generate’ program to keep the data set stirred up, making the odd-ball more obvious.
Best way to conquer randomness is with randomness.
@Andrew: Better yet, took the k2159 you posted, improved it. Your turn. Also have a bunch more to post, but your program should find them.
@xfxie: If you look at the graph I posted earlier, these particular tuples are in a gray valley, meaning they were not searched well, just used to try and improve the kb()-pi() values. Of the 40000 widths checked, only 100 widths above 10000 were of interest. Now that number is 30x more. The widths of all 4500 k0s are of interest.
@Thomas: Sorry I was tied up this afternoon, but when I got back my computer had found essentially the same sequences you posted for 2159 and 2161 (and several improvements nearby which I have posted), so nothing really new. It might be interesting for you to try an entirely new region (maybe another place where your curve looks suspiciously flat).
BTW, just to fill you in on a few details of the current incarnation of the “greedy-greedy” algorithm variants that xfxie and I are using, there are two stages: (1) pick a core set of residues at small primes (small meaning about sqrt(k*log(k)) or even a bit smaller) — this is the first “greedy” and is typically done by sieving shifted intervals at 1 mod 2 and 0 mod small primes and picking the one that yields the best results when you extend it greedily (the second greedy). (the shift is really just a convenient way to encapsulate a choice of core residue classes, and most of the time reasonably small shifts tend to give good core residues). (2) optimize a decent looking sequence output be (1) by iteratively merging it with randomly generated sequences with the same core residues, and then applying various random localized perturbations, e.g. swapping residue classes, adding and removing elements, etc….
Step (2) seems to work very well — in cases where we get (1) right we generally have no trouble matching your results even at small values at k where you have bounds that are either known to be optimal (k <= 342), or very likely to be optimal, and can do so quite quickly. Most of the time we can also do a good job with (1), but for certain "hard" values/regions of k we have trouble, and while in theory (2) "could" change one of the core residues, in practice it is very unlikely to happen because small changes to the core residues tend to make things much worse (the "good" sets of core residues are often very far apart). But I suspect you may be able to provide us with a wider variety of core residue sets to try.
@Andrew: just to make sure I understand your description of the iterative process. Take a shifted interval I and sieve out 1 mod 2 and 0 mod p for all small primes p to get a proto-tuple A which is admissible wrt small primes but not necessarily wrt large primes. Is it then true that all the sets generated by your iterative process are subsets of A (possibly after shifting I a little bit)? From your description it sounds like you always keep the residue classes at small primes and only move around the residue classes at large primes.
Also, how large a shift do you end up taking typically? Is the shifted interval usually shifted so that it does not contain the origin? If you search greedily over all shifts in some range, do you find that the best shift is more or less randomly distributed in that range, or do you find that small shifts (say) tend to be slightly better?
[ I was thinking of trying to do some sort of semi-rigorous asymptotic analysis of the “greedy-greedy” sieve (since it seems to give relatively good results) and in particular whether it asymptotically should do much better than the Schnizel sieve whose asymptotics were analysed semi-rigorously by Gordon and Rodemich, as the numerics suggest it does. In particular, all the sieves from Zhang to Schinzel give upper bounds on H(k_0) that are asymptotically of the form for some absolute constant C, and I’m wondering if the greedy-greedy sieve does better than this, perhaps by chipping away at the
for some absolute constant C, and I’m wondering if the greedy-greedy sieve does better than this, perhaps by chipping away at the 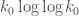 factor. ]
factor. ]
@Terence: Good questions! Let me give some clarifications (and I apologize in advance for the length).
(1) I don’t just sieve at small primes and pick the shifted interval that gives the largest number of survivors, instead I do a greedy extension of the small sieve at each tested shift and pick the shift that yields the best result on this basis (or maybe several shifts that look good). I originally tried exactly what you suggest, but it did not work as well. So the two “greedy”s really aren’t independent, the greedy choice of the core residue set is based on what happens when you extend greedily. Unfortunately I suspect this factor will make analysis more difficult (but I suspect one may still get a loglog gain by ignoring this issue)
(2) It is almost true that all of the subsequent tuples generated by the algorithm will be subsets of the survivors that remain after sieving mod small primes. However there are local perturbations that can, in theory, change a residue in the core set, but in practice rarely do, for example, the adjustment process described on the wiki is allowed to swap residue classes at any primes.
(3) For smaller values of k (I’m not sure where the cross over is but I think its between 5000 and 1000) the chosen interval does not contain the origin, but is relatively close to it, well within 1/2*k*log(k) (I check shifts out to k*log(k), but they basically never get used). For large values of k the chosen interval does contain the origin but it is not symmetric, it is shifted slightly (as in asymmetric H-R). I think this phenomenon can be readily analyzed. Basically it is a trade off between the cost of including the sparse region around the origin (the sieve will kill everything but powers of 2 near the origin) versus the benefit of staying in a range where the average gap between primes is smaller. In either case, small shifts away from either haveing the origin at the left or in the middle seem to consistently work best, its definitely not random. And I suspect one can even quantify the growth rate of “small”.
(4) I find it quite remarkable that small shifts work so well most of the time. If we instead simply sieved [0,d] and chose an arbitrary set of core residues, very few would correspond to small shifts — in principle one might need to go out to the product of the primes up to sqrt(k0*log(k0)). But in fact we can usually get optimal or very near optimal results just by going out to k0*log(k0), which is exponentially smaller (I say this from looking at k0 <= 342 where we know the optimal bound).
(5) Having said (4), there are cases where the optimal set of core residues does not correspond to a small shift. In order to match Engelsma's bound at 200 I did an exhaustive search of core residue sets at primes up to 23 (with a greedy extension), and was then able to easily match his bound using the best choice. The resulting set of residues corresponds to a shift value in the hundreds of thousands, way beyond the k0*log(k0) range. But this situation is the exception, not the rule. I originally thought this might be happening at 672 where we were unable to match Engelsma's 4998 bound for a long time, but it eventually was matched using a residue set corresponding to a small shift.
(6) An important caveat to everything I have said above, is that with the bulk-processing approach that I am now using, where throughout the optimization/perturbation process I am checking for good subsequences. This effectively allows lots of "small" perturbations to the core residue set, where "small" means a small change in the shift value, not a small number of residues changed (adding and removing points can also shift the interval).
@Andrew, would you be interested in writing a follow-up blog post? I feel bad that I haven’t done a new summary post, and allowed the number of comments here to get up to the zillions. But my math-on-the-internet time has been eaten by the MathOverflow migration!
A description of the server infrastructure, and however much you want to say about the heuristic behaviour of greedy-greedy would be great. You’d be welcome as a guest blogger here at the sbseminar, or to move to any venue that suited.
@Scott: I would be happy to write a follow-up blog post, my only issue is that I am heading to Europe tomorrow and need to prepare a talk I’m giving on Monday morning. Realistically, it would probably be Monday night or Tuesday before I could have it ready.
You have the same (good?) excuse I do! I’m walking to the BART station now to hop on a flight to Sydney!
@Thomas: Just did some updates on 4001-4050, seems most of them can be improved. I will try to run more on the region of your interest.
Hi
I have a question for those of you who are running greedy programs. Would some alternative solutions for small k, including ones where the optimum is already known, be of any use for you as seeds?
I have been too busy the last few weeks to keep up to date with all the nice work which has been done here so there might already be an answer somewhere earlier in the, rather long, thread which I haven’t seen.
I ask because I have a program which given an interval [a,b] can find the largest admissible tuple in that interval. It is based on integer programming so it might produce solutions which differs from the ones already found.
The drawback is that the machine where I can currently run this does not have quite as much RAM as one would need in order to go up to intervals of length say 7000.
@Klas: This could definitely be useful. One of the things I would like to do (eventually) is to have the tuple database accept multiple submissions with the same record diameter if they happen to use a different set of “core residues” (meaning the list of unoccupied residue classes at small primes, say primes up to the square root of the diameter). The choice of the initial set of core residues is probably the least optimized aspect of the greedy algorithms we have been using, and I expect that there is still significant progress that can be made here.
In general, a good set of core residues for one value of k will also work well for nearby values of k, where “nearby” probably means within, say, a few percent. But even if you can’t get close to k0=902 (with current diameter bound 6966), it would still be interesting to see what happens at smaller values of k, especially if you can get above k=342 with diameter 2328 (I believe Engelsma has a complete list of all optimal admissible tuples of diameter up to 2328, although this data is not currently available).
How large an interval can you handle?
I sympathize with the thread length issue. Scott has asked me to write a summary so that we can roll the blog over and start a new thread. Unfortunately I’m traveling today and tomorrow, so this won’t happen until early next week.
So I just did a remote check on the submission server to make sure it was still up and I saw that xfxie has been submitting a flurry of new records, nearly 200 in the past hour with more coming in every minute.
Well done!
@xfxie: I assume you put together a script to automate the submission process. Is this in a form that would be easy to make available to others?
@andrew: unfortunately, I submitted them by manual (although somewhat fast) and actually I feel quite tired by now. I thought to write a automatic submitter, but the form/script on the server seems to be too complicated for me. I noticed some websites support submitting multiple files in a submit form, but i do not know how easy for you to implement that.
I have a couple of times got a 403 error (You don’t have permission to access /~primegaps/ on this server.) when trying to access the primegaps page. Reloading fixes the problem. Why does this occur?
@Andrew
I’ll set my program up to produce optimal tuples for intervals of increasing size and make them available so you can try them out.
I’m not sure how far I can push this now. The program seems to find a near optimal tuple fairly quickly for short intervals, ie. a few hundred in length, then spend a little more time before it finds an optimal tuple and finally a substantially longer time on proving that the tuple is optimal.
In principle I could try to split the problem into cases and use a linux cluster to solve the cases, but before going as far as that I’d prefer to know that we have an interval which i relevant for the project.
Another thing which I could modify my program to do is to find all largest admissible tuples for an interval. How far this can be done will depend on how many optimal tuples there are.
No hurry with the new write up. I’m also traveling to the UK today actually sitting at the airport in Stockholm waiting for my connecting flight when I write this.
@xfxie: I will try to put together something to handle multiple submissions as soon as I can. I’m tied up most of the day tomorrow, so it may be Tuesday before I get to it. Sorry for the hassle!
@Hannes: I have seen the 403 problem myself a few times, and it is also happening on my home page. It may have something to do with our recent server relocation (the math department is undergoing some major renovation and they moved all the servers last week). I’ll check with the IT folks tomorrow.
@Klas: Any improvement on the upper bounds we have in the
tables at http://math.mit.edu/~primegaps/ would be of interest (independent of where k0 winds up, there are other reasons to want good bounds on H(K)). So if you think you can get some new bounds for some smallish k > 342 (for k 342 are optimal, that would be of great interest, but I expect that involves a lot more computation). At this stage I think it’s fair to say we still don’t know what the “final” k0 will be, so I wouldn’t burn a huge amount of effort on a particular k0 (or interval size).
I have another question. Has anyone looked into whether there are optimal sequences, for k<=342, which have initial segments which are optimal for other smaller values of k as well?
@klas: Yes! This happens a lot. As an example, for k=100 consider the optimal sequence
http://math.mit.edu/~drew/admissible_100_558.txt
Simply truncating that sequence gives optimal sequences for k=99,98,97,96,95,94,93. These all have the same unsieved residue classes modulo the first 12 primes (up to p=37), namely
1 1 4 3 5 1 4 9 11 10 15 14
(and at p=41 there is more than one unoccupied class). One can then also look at the unique extension of a sequence obtained by adding the first point after the last that yields an admissible sequence. Applying this to the above sequence gives optimal sequences at k=101,102,103, and again these all have the same unoccupied residues modulo the first 12 primes. So all together we get 11 optimal sequences from the single sequence above.
(Side comment, I still plan to have the submission server automatically check all new submissions to see if additional records can be obtained via truncation/extension, but I have not had time to put this check in).
I should note that the sequence above is not quite the same as the one listed in the tuple database for k=100. The sequence
http://math.mit.edu/~primegaps/tuples/admissible_100_558.txt
is basically its mirror image (at least at the ends), and you need to reduce/extend at the start of the sequence rather than at the end. This means that when if you then translate the result to 0 (our standard starting element), the values of all the unsieved residue classes get shifted and don’t look the same anymore.
The moral is that finding one really good sequence will often give you a bunch of others. This is one of the reasons the tuple database has seen so many updates over the past 48 hours (more than 800 new records), one breakthrough sequence can trigger new records at a bunch of nearby k’s, and xfxie and I have been hitting a lot these.
So now I have a question for Thomas: what is the minimal number of tuples you need in order to be able to generate all the optimal sequences for k <= 342 via truncation and extension? Based on the example above, it might be pretty small (I realize that it might not be easy for you to figure out the exact number, but a rough guess would still be interesting).
Regarding the chart Thomas posted in #377, here is an up to date and more detailed version
that I also posted at http://terrytao.wordpress.com/2013/06/30/bounded-gaps-between-primes-polymath8-a-progress-report/#comment-236908.
I am getting a clearer idea of why it seems so effective to sieve out 0 mod p for small primes (with the possible exception of tiny primes such as p=2). For simplicity let me only sieve out of the interval [1,x], although the analysis here also works with minor modifications for shifted intervals. Also to simplify the discussion we will sieve out 0 mod 2 rather than 1 mod 2 even though the latter gives slightly better results.
Basically it’s the sieve of Eratosthenes: if one sieves out 0 mod p for all primes p up to on [1,x], then one has automatically also sieved out almost all of 0 mod p for primes larger than
on [1,x], then one has automatically also sieved out almost all of 0 mod p for primes larger than 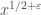 , since the only survivors of the sieve in this residue class consist of
, since the only survivors of the sieve in this residue class consist of  (it would be
(it would be  instead if one did not sieve out 0 mod 2). This should be compared with the expected number of survivors in a given residue class mod p for a sifted set of size about x/log x, which should be about x/(p log x). Thus for all primes p between
instead if one did not sieve out 0 mod 2). This should be compared with the expected number of survivors in a given residue class mod p for a sifted set of size about x/log x, which should be about x/(p log x). Thus for all primes p between 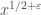 and, say,
and, say, 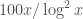 , it makes sense to kill off the rest of
, it makes sense to kill off the rest of  since one is losing so few elements this way (basically about
since one is losing so few elements this way (basically about  ). For p much larger than, say
). For p much larger than, say 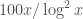 there should be no need to sieve at all: the number of survivors in any residue class should heuristically be distributed according to a Poisson process of intensity
there should be no need to sieve at all: the number of survivors in any residue class should heuristically be distributed according to a Poisson process of intensity  or less, and since there are p residue classes, we expect with quite high probability that at least one of these residue classes turns up empty already.
or less, and since there are p residue classes, we expect with quite high probability that at least one of these residue classes turns up empty already.
So, suppose one sieves out 0 mod p from [1,x] for all primes less than , and also between
, and also between 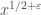 and
and 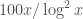 . The only survivors (apart from 1, which we will ignore) are then the large primes (the ones between
. The only survivors (apart from 1, which we will ignore) are then the large primes (the ones between 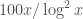 and
and  ), as well as the product of two medium primes (the ones between
), as well as the product of two medium primes (the ones between  and
and 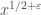 ). The number of large primes is basically
). The number of large primes is basically
while the number of products of two medium primes is basically
which by Mertens’ theorem can be computed to be about
So the products of medium primes are potentially adding a significant number of new elements to the tuple, boosting by a multiplicative factor of . The price one pays for this is that one has not yet sifted out all the primes: one still has to sieve out one residue class mod p for every prime between
. The price one pays for this is that one has not yet sifted out all the primes: one still has to sieve out one residue class mod p for every prime between  and
and 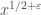 . If one sieves these primes out randomly, one expects to reduce the number of survivors by a factor of
. If one sieves these primes out randomly, one expects to reduce the number of survivors by a factor of
which by Mertens’ theorem is about
so we kill slightly more survivors than we gained. But this is from the random sieve; one can imagine that a cleverer sieve saves a few more survivors and tips the balance, which may help explain why it is sometimes advantages to stop the Schinzel sieve a bit before .
.
A few quick comments on #405:
(1) Heuristically, the largest prime for which you need to sieve a residue class in order to get an admissible k-tuple is approximately , or
, or  for
for  .
.
(2) One might try to sharpen the analysis by assuming that you sieve the least occupied residue class for primes in![[x^{1/2-\epsilon},x^{1/2+\epsilon}]](https://s0.wp.com/latex.php?latex=%5Bx%5E%7B1%2F2-%5Cepsilon%7D%2Cx%5E%7B1%2F2%2B%5Cepsilon%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) , rather than a random class, using a balls-in-bins analysis to estimate the ratio of the expected # of balls in the minimally occupied bin relative to the total # of balls.
, rather than a random class, using a balls-in-bins analysis to estimate the ratio of the expected # of balls in the minimally occupied bin relative to the total # of balls. to something like
to something like  , but unfortunately this doesn’t give a constant factor improvement.
, but unfortunately this doesn’t give a constant factor improvement.
I think this changes the factor
(3) If you sieve 0 mod 2 instead of 1 mod 2, it’s actually critical to stop below , otherwise you are likely to wind up sieving 0 mod
, otherwise you are likely to wind up sieving 0 mod  for all primes
for all primes  (i.e. the residue class 0 will remain as good as any other for all remaining primes). But this is not true if you sieve 1 mod 2.
(i.e. the residue class 0 will remain as good as any other for all remaining primes). But this is not true if you sieve 1 mod 2. for
for  , and the greedy choice first deviates from sieving 0 mod
, and the greedy choice first deviates from sieving 0 mod  at about $\sqrt{k_0\log k_0}$, but your analysis makes me think that perhaps I should stop sieving 0 mod
at about $\sqrt{k_0\log k_0}$, but your analysis makes me think that perhaps I should stop sieving 0 mod  sooner.
sooner.
Currently I am sieving 1 mod 2 and then 0 mod
(4) Regarding the shift, in checking the data I see that for intervals to the right of the origin, the best choice tends to be on the order of (typically between
(typically between  and
and  ), or
), or  in terms of
in terms of  . When sieving 0 mod
. When sieving 0 mod  it's clear that it makes sense to ignore 1 and shift at least to the first unsieved prime. And perhaps one can show that if we sieve
it's clear that it makes sense to ignore 1 and shift at least to the first unsieved prime. And perhaps one can show that if we sieve ![[1,x]](https://s0.wp.com/latex.php?latex=%5B1%2Cx%5D&bg=ffffff&fg=444444&s=0&c=20201002) at 0 mod
at 0 mod  for
for  up to
up to  , then an
, then an  shift is justified.
shift is justified.
@Andrew
I have collected the tuples I have produced so far here
http://abel.math.umu.se/~klasm/Data/adm-tuples/
The file name indicates the interval that was used and the size of the largest tuple that was found. The actual diameter for the is not part of the name but is typically lower than the diameter of the interval and agrees with the known optimal bounds.
Hopefully these tuples will look a bit different from the ones found by other approaches.