Everyone by now has heard about Zhang’s landmark result showing that there are infinitely many pairs of primes at most 70000000 apart.
His core result is that if a set of 3.5 * 10^6 (corrected, thanks to comment #2) numbers  is admissible (see below), then there are infinitely many
is admissible (see below), then there are infinitely many  so that
so that 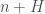 contains at least two primes. He then easily constructs an admissible set wherein the largest difference is 7 * 10^7, obtaining the stated result.
contains at least two primes. He then easily constructs an admissible set wherein the largest difference is 7 * 10^7, obtaining the stated result.
A set is admissible if there is no prime  so
so  occupies every residue class. For a given this is clearly a checkable condition; there’s no need to look at primes larger than
occupies every residue class. For a given this is clearly a checkable condition; there’s no need to look at primes larger than  .
.
(While Zhang went for a nice round number, Mark Lewko found his argument in fact gives 63374611, if you’re being overly specific about these things, which we are right now. :-)
In a short note on the arXiv yesterday, Tim Trudgian (whose office is not far from mine) pointed out another way to build an admissible set, giving a smaller largest difference, obtaining the result that there are infinitely many pairs of primes at most 59874594 apart. He considers sets of the form 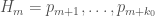 (where
(where  is Zhang’s constant 3.5 * 10^7). These aren’t necessarily admissible, but they are for some values of
is Zhang’s constant 3.5 * 10^7). These aren’t necessarily admissible, but they are for some values of  , and both Zhang and Tim noticed certain values for which this is easy to prove. Zhang used
, and both Zhang and Tim noticed certain values for which this is easy to prove. Zhang used  with
with  , while Tim’s observation is that
, while Tim’s observation is that 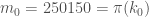 also works. (Comment #2 below points out this isn’t right, and Zhang also intended
also works. (Comment #2 below points out this isn’t right, and Zhang also intended 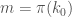 , and the slack in his estimate is coming from just looking at the largest element of , rather than the largest difference.) Thus the bound in his result is
, and the slack in his estimate is coming from just looking at the largest element of , rather than the largest difference.) Thus the bound in his result is 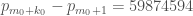 .
.
It turns out that checking admissibility for a given isn’t that hard; it takes about an hour to check a single value for  (but if you find a prime witnessing not being admissible, it very often gives you a fast proof that
(but if you find a prime witnessing not being admissible, it very often gives you a fast proof that  is not admissible either, so searching is much faster).
is not admissible either, so searching is much faster).
I haven’t looked exhaustively, but one can check that 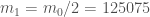 gives an admissible , and hence there are infinitely many pairs of primes at most
gives an admissible , and hence there are infinitely many pairs of primes at most 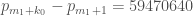 . (Sadly, it’s impossible to get below 59 million with this trick; no below 27000 works; all witnessed by
. (Sadly, it’s impossible to get below 59 million with this trick; no below 27000 works; all witnessed by  or
or  .)
.)
I just couldn’t resist momentarily “claiming the crown” for the smallest upper bound on gap size. :-) Of course the actual progress, that’s surely coming soon from people who actually understand Zhang’s work, is going to be in reducing his 3.5 * 10^6. You can read more about prospects for that in the answers to this MathOverflow question.

WordPress ate my LaTeX…?
Trudgian’s set is actually the same one Zhang said to construct in the first place. From Zhang’s paper: “The bound (1.5) results from the fact that the set H is admissible if it is composed of k_0 distinct primes, each of which is greater than k_0, and the inequality
π(7 * 10^7) − π(3.5 * 10^6) > 3.5 * 10^6.” Among the first 3.5 * 10^6 primes above 3.5 * 10^6, the largest is 63374611 as pointed out by Lewko, but the smallest is 3500017, and their difference is 59874594. (The number Zhang uses is 3.5 * 10^6, not 3.5 * 10^7.)
#2, indeed you’re right!
It’s still not right: the numbers are 3.5*10^6 and 7*10^7, since there are at least 3.5*10^6 primes between 3.5*10^6 and 7*10^7.
Oops, thanks.
This is a silly comment, but it’s been irritating me to see people publicly using an odd number as the bound, so let me point out that Mark Lewko’s observation can be trivially improved from 63374611 to 63374610.
In the notation of this paper of Richards, one can find an admissible set of diameter at most D and cardinality
of diameter at most D and cardinality  if and only if
if and only if 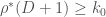 . Now, in the above paper of Richards, it is shown that
. Now, in the above paper of Richards, it is shown that 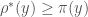 for sufficiently large y (in fact the difference goes to infinity), and in fact the first crossover is known to occur at
for sufficiently large y (in fact the difference goes to infinity), and in fact the first crossover is known to occur at 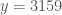 , according to Wikipedia. It is thus very likely that the arguments of Richards will be able to establish that
, according to Wikipedia. It is thus very likely that the arguments of Richards will be able to establish that 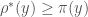 for all $y$ larger than, say, 50 million. If so, this will give prime gaps of size at most
for all $y$ larger than, say, 50 million. If so, this will give prime gaps of size at most  whenever
whenever  . which gives a bound of 58,885,998. (But this is conditional on Richards’ theorem kicking in by this threshold.)
. which gives a bound of 58,885,998. (But this is conditional on Richards’ theorem kicking in by this threshold.)
Presumably if one dives into arguments of the Richards paper as well as followups to that 1974 paper, one can obtain further improvements.
Now that I actually took a look at Richard’s argument, the new trick is really simple: instead of looking at a consecutive sequence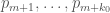 , take instead
, take instead 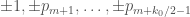 as this has similar admissibility properties but can be slightly narrower. I haven’t done the numerical optimisation though; perhaps someone else is willing to have the next shot at the world record?
as this has similar admissibility properties but can be slightly narrower. I haven’t done the numerical optimisation though; perhaps someone else is willing to have the next shot at the world record?
Update: my computer finished running, and the least m that works as above is 33639, giving a bound of 59,093,364.
(There’s also a comment thread on this topic on Terry Tao’s google+ post at https://plus.google.com/114134834346472219368/posts/39tuzQ8npYt)
My computer just finished looking through values of m that might work in Richard’s sequence described in Terry’s comment #8 above. As it turns out m=36716 is the least m so that that sequence is admissible. The biggest difference in that sequence is 2 p_{36716+k_0/2-1} = 57,554,086, giving a new best upper bound on prime gaps.
Scott, why not write a one-page article and put it on the archive (you could call it “An even poorer man’s improvement…”) :-P Due credit to Terry of course.
archive -> arXiv :-S
Well, it’s unlikely that this new “record” will last more than a week. For instance, it should be easy to reduce the value of a little bit simply by not rounding off in Zhang’s paper, which will immediately improve the bound
a little bit simply by not rounding off in Zhang’s paper, which will immediately improve the bound 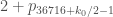 that Scott found (note that as
that Scott found (note that as  works for
works for 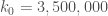 , it automatically works for smaller values of
, it automatically works for smaller values of  as well).
as well).
Perhaps this blog post could serve as a clearing house for the “sport” of tweaking the bounds though. Even if these improvements don’t add up to much in the grand scheme of things (the current record is only about a 10% improvement over what Zhang really gets if one doesn’t keep rounding up), it’s actually not that bad of an excuse to get one to understand what’s going on in Zhang’s paper.
In case anyone wants to do the optimisation: Zhang’s argument gives his Theorem 1 for a given value of provided that one can find a natural number
provided that one can find a natural number 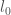 such that
such that  , where
, where  , and
, and 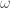 is a complicated but explicit function of
is a complicated but explicit function of 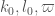 ; see the end of Section 5.
; see the end of Section 5. 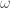 is defined after (5.7) in terms of
is defined after (5.7) in terms of 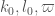 and two small quantities
and two small quantities 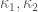 , which are defined after (4.19) and (5.5) respectively in terms of
, which are defined after (4.19) and (5.5) respectively in terms of 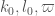 and two further quantities
and two further quantities  depending on
depending on  that are defined in (4.10). (4.14). Zhang ends up taking
that are defined in (4.10). (4.14). Zhang ends up taking 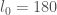 . It seems like a routine computer search could obtain the optimal
. It seems like a routine computer search could obtain the optimal  that this method gives for the given value of
that this method gives for the given value of  . (The novel part of Zhang’s argument lies in the fact that he for the first time was able to get a positive value of
. (The novel part of Zhang’s argument lies in the fact that he for the first time was able to get a positive value of  ; improving that value would presumably propagate to improved values of
; improving that value would presumably propagate to improved values of  , and hence to the gap bound.)
, and hence to the gap bound.)
Minor comment; in Terry’s #14 the formula for the latest bound should be , rather than
, rather than 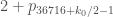 .
.
I made a little mathematica notebook with the relevant formulas, and found the best value of that works with Zhang’s method.
that works with Zhang’s method.
The least for which there is some
for which there is some 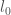 so
so 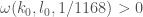 is 2947442, (which works for
is 2947442, (which works for  and no other). For reference
and no other). For reference 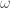 at these parameters is
at these parameters is 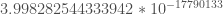 ; pretty tiny!
; pretty tiny!
I haven’t re-run the search for the best with this new value of
with this new value of  , but right away we get a new bound on prime gaps of
, but right away we get a new bound on prime gaps of
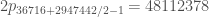 , so hooray, we’re below 50 million. :-)
, so hooray, we’re below 50 million. :-)
Scott, how long do you think before you now optimize m? Once you do, I suppose then it will take some delving into how is arrived at (and yes, I know this is a whole lot harder).
is arrived at (and yes, I know this is a whole lot harder).
Terry: Where does Zhang pluck 1/1168 from?
Great! Incidentally, almost all of the smallness of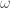 is due to the factor of
is due to the factor of  at the front of its definition, which is ultimately irrelevant for the question of whether
at the front of its definition, which is ultimately irrelevant for the question of whether 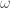 is positive or not (but this smallness does highlight the fact that Zhang’s argument takes a VERY long time before actually producing pairs of primes with small gaps). The positivity of
is positive or not (but this smallness does highlight the fact that Zhang’s argument takes a VERY long time before actually producing pairs of primes with small gaps). The positivity of 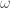 can be rearranged as
can be rearranged as
which helps highlight what needs to happen for the inequality to hold, namely that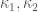 be small, and that
be small, and that 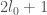 be close to both
be close to both  and
and  .
.
This project is curiously addictive; I guess because it is much easier to make progress on it than with more normal research projects :). I think the next lowest hanging fruit is to improve the estimation of the quantity , which is currently quite huge; I think I can essentially get rid of the
, which is currently quite huge; I think I can essentially get rid of the 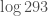 term in the definition of
term in the definition of  , which should give another 10% or 20% improvement in the final bound, but I am still working out the details here (it does require a little bit of standard analytic number theory to get the improvement). More later…
, which should give another 10% or 20% improvement in the final bound, but I am still working out the details here (it does require a little bit of standard analytic number theory to get the improvement). More later…
My current very simple program for checking admissibility of these sequences will take a few hours. I do know how to write something much more efficient, but it would be ~100 lines of code, rather than ~10, so it may not happen. In any case, it’s running with the new value of k_0 so we’ll know soon if there’s any further to squeeze out there.
OK, I wrote up an argument at http://terrytao.files.wordpress.com/2013/05/bounds.pdf that shows that one can take to be
to be 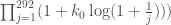 instead of
instead of  , which basically amounts to eliminating the
, which basically amounts to eliminating the 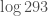 factor as I mentioned previously, and should lead to an improvement of somewhere between 10% and 20% in the final analysis, though I didn’t run the computations.
factor as I mentioned previously, and should lead to an improvement of somewhere between 10% and 20% in the final analysis, though I didn’t run the computations.
@David: after a lengthy argument (Sections 6-14), Zhang needs a certain expression (13.16) to be bounded by , but instead gets a bound of
, but instead gets a bound of  . The value of
. The value of 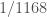 is then the first value of
is then the first value of  for which the argument closes. I haven’t read the arguments in detail in these areas yet, though.
for which the argument closes. I haven’t read the arguments in detail in these areas yet, though.
That gets us down to . Current bound is thus
. Current bound is thus  .
.
Oh, and m=30798 just came in for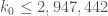 , giving the infinitesimal improvement to
, giving the infinitesimal improvement to 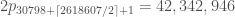 .
.
Good to know! But I think we’re approaching the point of diminishing returns unfortunately :). As far as I can tell, to make any serious further improvements the only two options are to (a) go seriously through the “hard” part of Zhang’s paper (Sections 6-13) and try to save some factors of somewhere in the final inequality
somewhere in the final inequality 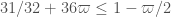 (or get some additional cancellation that moves
(or get some additional cancellation that moves  further away from 1) or else (b) play the Goldston-Pintz-Yildirim game (Sections 3-5) with the sieve weighting function
further away from 1) or else (b) play the Goldston-Pintz-Yildirim game (Sections 3-5) with the sieve weighting function  replaced by a more general function of
replaced by a more general function of  to optimise in. (To see the type of improvement this gives in the original Goldston-Pintz-Yildirim paper for various values of
to optimise in. (To see the type of improvement this gives in the original Goldston-Pintz-Yildirim paper for various values of  (which roughly corresponds to
(which roughly corresponds to  in Zhang’ paper), compare the table on page 9 of http://arxiv.org/pdf/math/0508185.pdf (which uses the standard GPY weights
in Zhang’ paper), compare the table on page 9 of http://arxiv.org/pdf/math/0508185.pdf (which uses the standard GPY weights  ) with the table on page 12 (which uses more general functions)). On the other hand, Zhang’s modifications of the GPY method have these additional terms
) with the table on page 12 (which uses more general functions)). On the other hand, Zhang’s modifications of the GPY method have these additional terms 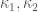 which appear to dominate the analysis, so the numerical improvement here may end up being negligible.
which appear to dominate the analysis, so the numerical improvement here may end up being negligible.
I might have a stab at both (a) and (b) for the purposes of understanding the Zhang argument better, but these are not as easy tasks as the previous low-hanging fruit and are likely to take weeks rather than days. My guess is that (b) is doable but will give another modest improvement of the type we’ve already been achieving (i.e. 10% or so), whereas (a) is conceptually more difficult (one has to understand all the new ideas in Zhang’s paper) but has the potential for a more significant improvement (e.g. doubling ). Note that
). Note that  roughly speaking grows like
roughly speaking grows like  , so every doubling of
, so every doubling of  should decrease
should decrease  by a factor of 4 or so; meanwhile, the gap bound
by a factor of 4 or so; meanwhile, the gap bound  behaves like
behaves like 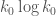 and so should also improve by a factor of a bit more than 4.
and so should also improve by a factor of a bit more than 4.
Actually, it looks like there is considerable room to improve the estimation of the quantity , which is currently being controlled in terms of the very large quantity
, which is currently being controlled in terms of the very large quantity  (which remains rather large even after the improved estimate given previously), which may lead to a significant improvement to
(which remains rather large even after the improved estimate given previously), which may lead to a significant improvement to  even without attempting either of (a) and (b) above. I’ll try to write up some details soon.
even without attempting either of (a) and (b) above. I’ll try to write up some details soon.
OK, the details are at http://terrytao.files.wordpress.com/2013/06/bounds.pdf . Assuming I have not made a mistake, I believe I can now improve the quantities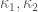 in Zhang’s analysis considerably by replacing the terms involving
in Zhang’s analysis considerably by replacing the terms involving  with a significantly smaller expression. More specifically, whereas Zhang takes
with a significantly smaller expression. More specifically, whereas Zhang takes
and
one can now take
and
where
(One can replace all factors of with 292 when
with 292 when  , which is the source of all the 292’s in formulae mentioned in previous comments.)
, which is the source of all the 292’s in formulae mentioned in previous comments.)
The point is that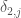 is usually much smaller than
is usually much smaller than  except when
except when  is close to
is close to  , but in that case one gets many powers of the extremely small quantity
, but in that case one gets many powers of the extremely small quantity 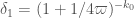 (rather than just one such power, as in Zhang’s original paper).
(rather than just one such power, as in Zhang’s original paper).
This should lead to a substantial improvement in the value of – perhaps by a factor of two or more – and thus also for the final gap bound. (Incidentally, a tiny improvement to the previous gap: when
– perhaps by a factor of two or more – and thus also for the final gap bound. (Incidentally, a tiny improvement to the previous gap: when  is odd one can delete one of the extreme primes leading to a gap of
is odd one can delete one of the extreme primes leading to a gap of 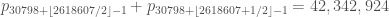 , if I computed correctly.)
, if I computed correctly.)
Sorry, let me try again and manually put in a line break: the new formulae for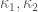 should be
should be
and
Wow, Terry’s new formulas for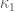 and
and  coming from better estimates for
coming from better estimates for  bring
bring  all the way down to 866,805 (which works for
all the way down to 866,805 (which works for  ).
).
Happily finding the least that works in Richard’s sequence is now reasonably fast. For
that works in Richard’s sequence is now reasonably fast. For  , $m=11651$ is the first that works, giving the latest bound of
, $m=11651$ is the first that works, giving the latest bound of
Thanks for the data! I think I will try to write up a self-contained blog post describing the path from a given choice of to bounds on
to bounds on  (there are now sufficiently many deviations from Zhang’s argument that it becomes a bit difficult to follow the argument purely from describing the modifications to Zhang’s paper, as I did in the previous link). There is a bit of room to estimate Zhang’s error terms
(there are now sufficiently many deviations from Zhang’s argument that it becomes a bit difficult to follow the argument purely from describing the modifications to Zhang’s paper, as I did in the previous link). There is a bit of room to estimate Zhang’s error terms  further, but there’s not going to be any further dramatic savings like the one we just saw; instead, there is probably just 10% or 20% to be squeezed out of further optimisation of this step in my opinion.
further, but there’s not going to be any further dramatic savings like the one we just saw; instead, there is probably just 10% or 20% to be squeezed out of further optimisation of this step in my opinion.
It’s quite entertaining to watch the ongoing discussion. Do you think it makes sense to create a community wiki thread on mathoverflow.net to concentrate these efforts on one place?
If I understood correctly, the admissible set $H$ doesn’t need to consist of primes only. I hacked together a small program to see the behaviour and it turns out that if one allows for nonprimes then the ratio of diameter and length is approximately 10. (So far I’ve produced admissible set of diameter 64992 and length 5632. Only 1506 of those numbers are primes.) Hence it should be possible to find an admissible set of length 866,805 with diameter around 9,000,000. Possibly breakig the psychological barrier of 10 millions.
If I have time I’ll try to optimize memory requirements of my program and see how far I can push it.
Hi Vít,
that’s a nice idea. I thought about doing the same, but wasn’t sure if it would actually be possible to “search”. How are you deciding which sequences to look at?
I remember seeing some lower bounds on the diameter of an admissible set of given length; I wonder how far off those we still are.
One possibility would be to pick, for each prime p, a “forbidden residue class” i_p, and then just take the first k_0 non-forbidden numbers. (E.g. the original sequence, just a list of primes, comes from having the forbidden class be 0 for some initial sequence of primes, then, say, 1 after that.) You might imagine then “searching” this space, by changing one forbidden residue at a time to see if you can decrease the diameter.
It’s not entirely clear mathoverflow is better than a blog comment thread for this, but I guess I’d be happy to move if someone wrote the appropriate question.
Something like “Can the techniques of Morrison-Tao be used to get the prime gap bound below 10 million?” If the answer is yes or no, then either way one could explain how to do so, possibly using Vít Tuček’s suggestion. I would like to see at least a push to get below 7M, one factor of ten over Zhang’s bound, which feels like a real milestone (or below 1M, but that looks unlikely).
It depends on how long can we play this game. If there’s not much more to be expected than what is written on this page and Terrence’s blog then it doesn’t make much sense. I just thought that exposing this fun to a wider audience can be benefactory. Also, possibility of editing one’s posts adds a lot to clarity of exposition. I have actually half-written the question but then I decided to ask here first. If there’ll be no objections here by tomorrow morning (in GMT+1) I’ll post the question and see if it sticks.
As for my admissible set; I just basically start with 1 and work my way towards bigger numbers crossing off those which destroy admissibility.
Ideally people would make their code accessible (at some point), so people would have the benefit of access to that as well as Terry’s write-up on improving the theoretical bounds. This might lead to some optimisation on slow searching algorithms.
Regarding the possible length of an admissible k-tuple, there’s a well-known explicit estimate of Montgomery and Vaughn that gives
Since this is proven via sieve theory it should hold for admissible k-tuples as well (or, for that matter, if you believe the k-tuples conjecture). Thus solving gives
gives  around $6.8$ million, which will be a hard lower bound on the distance of a k-tuple with
around $6.8$ million, which will be a hard lower bound on the distance of a k-tuple with  . My guess is that this is probably significantly smaller than one can really achieve. If I recall correctly Richards conjectures that the correct asymptotic is
. My guess is that this is probably significantly smaller than one can really achieve. If I recall correctly Richards conjectures that the correct asymptotic is 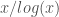 which saves an asymptotic factor of
which saves an asymptotic factor of  , but then you need explicit bounds on the error terms to be of use here…
, but then you need explicit bounds on the error terms to be of use here…
The literature on the topic seems surprisingly sparse.
@David, thanks for the reminder! My code (mathematica) containing the formulas for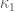 and so on, and Terry’s updates to them, as well as a very simplistic method for finding the optimal
and so on, and Terry’s updates to them, as well as a very simplistic method for finding the optimal  , is available at http://tqft.net/misc/finding%20k_0.nb
, is available at http://tqft.net/misc/finding%20k_0.nb
(It would be great if someone could check it for typos!)
My current code for optimising for a given
for a given  is a little hard to disentangle from other stuff, but I’ll see what I can do. It’s written in Scala.
is a little hard to disentangle from other stuff, but I’ll see what I can do. It’s written in Scala.
For people interested in numerically optimising the width of admissible tuples of a given size, there is a table at
http://www.opertech.com/primes/k-tuples.html
computing the narrowest k-tuples (the width is called w in that page) up to k=342, together with some upper bounds up to k=672, plus some other data.
Richards’ paper linked to above is also an easy (and rather entertaining) read.
I’m in the middle of writing a sieve-theoretic blog post describing the procedure to convert a value of to a value of
to a value of  , hopefully it should be done in a few days.
, hopefully it should be done in a few days.
Incidentally I believe now that the parameter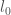 in Zhang’s paper can be taken to be real instead of integer (but one has to replace certain factorials and binomial coefficients with Gamma functions and Beta functions in the usual fashion). This would lead to a very very tiny improvement in the value of
in Zhang’s paper can be taken to be real instead of integer (but one has to replace certain factorials and binomial coefficients with Gamma functions and Beta functions in the usual fashion). This would lead to a very very tiny improvement in the value of  (reducing it by maybe 1 or 2), so this is probably not worth implementing unless someone really has a lot of time on their hands. :)
(reducing it by maybe 1 or 2), so this is probably not worth implementing unless someone really has a lot of time on their hands. :)
@Vit,
I’m dubious that greedily looking for admissible sequences will work. I looked (starting at 0 rather than 1, as you did, so the results aren’t directly comparable) and by length 6,000 I had width 61,916 (beating your example), but by length 866,000 I had width 13,824,018, indicating this doesn’t improve upon the current method (of using Richard’s sequence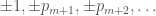 for some
for some  ).
).
One might try being “not so greedy”, but given the purely greedy method is a fair way behind it seems unlikely. I don’t see so far any way to search incrementally, rather than just stumbling randomly around the landscape of “almost greedy” admissible sequences.
http://mathoverflow.net/questions/132632/tightening-zhangs-bound
If I am not mistaken, Ramanujan primes can bring the value of H down.
I just finished the blog post at
http://terrytao.wordpress.com/2013/06/03/the-prime-tuples-conjecture-sieve-theory-and-the-work-of-goldston-pintz-yildirim-motohashi-pintz-and-zhang/
I now understood the procedure of converting bounds on to bounds on
to bounds on  to the point where I could work out my own argument instead of modifying Zhang’s one. (Actually the argument I ended up with is close in spirit to an earlier paper of Motohashi and Pintz which had a similar idea to the first half of Zhang’s paper, namely to smooth out the Goldston-Pintz-Yildirim sieve). As a consequence we have a much better dependence of constants. The needed constraint is now of the form
to the point where I could work out my own argument instead of modifying Zhang’s one. (Actually the argument I ended up with is close in spirit to an earlier paper of Motohashi and Pintz which had a similar idea to the first half of Zhang’s paper, namely to smooth out the Goldston-Pintz-Yildirim sieve). As a consequence we have a much better dependence of constants. The needed constraint is now of the form
where is now a much smaller quantity:
is now a much smaller quantity:
In the case , this is
, this is
and will be exponentially small in practice. As before,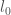 is now free to be real instead of integer, although this is unlikely to lead to any dramatic improvements.
is now free to be real instead of integer, although this is unlikely to lead to any dramatic improvements.
This should get down to very near the theoretically best possible value of
down to very near the theoretically best possible value of  for this value of
for this value of  (which is what one gets if one ignores
(which is what one gets if one ignores  ).
).
This leaves us with three further avenues for improvement: (a) finding narrower admissible tuples of a given size than the Richards examples; (b) optimising the cutoff function g in the Motohashi-Pintz-Zhang argument (this is a calculus of variations/ODE/spectral theory/microlocal analysis type problem, the game being to optimise the ratio between the two integrals in (14) of the linked blog post), and (c) improving Zhang's value of .
.
Regarding a future venue for this sort of thing, a polymath project could be more appropriate than a mathoverflow post; it seems like there are enough independent things to do (e.g. I could run a reading seminar on the second half of Zhang's paper for goal (c) while others work on (a) and (b)) and maybe enough participants that this could be viable.
The question on mathoverflow has just been closed. I sincerely hope that there actually will be a polymath project.
Here are three comments on dense prime constellations:
(I had posted this earlier, but probably went into the spam filter, so I try as three individual items)
1) The paper by Gordon and Rodemich “Dense admissible sets”
has some useful information.
http://www.ccrwest.org/gordon/ants.pdf
This paper and also Hensley and Richards (“Primes in intervals”)
matwbn.icm.edu.pl/ksiazki/aa/aa25/aa2548.pdf
both mention an observation of Schinzel on a variant of the sieve of
Eratosthenes.
While one usually sieves the class , for
, for 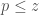 , one now sieves the class
, one now sieves the class 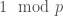 , for
, for
 and the class
and the class  for
for 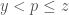 .
.
It seems that one can increase a dense cluster of primes from about
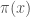 to
to  , where
, where  is larger than in the Hensley-Richards trick using the interval
is larger than in the Hensley-Richards trick using the interval ![[-x/2,x/2]](https://s0.wp.com/latex.php?latex=%5B-x%2F2%2Cx%2F2%5D&bg=ffffff&fg=444444&s=0&c=20201002) . (For details see the paper by Gordon and Rodemich).
. (For details see the paper by Gordon and Rodemich).
As all this influences only the second order term,
the improvement coming from here is limited.
And indeed, with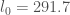 , Terry’s #47 allows the optimal
, Terry’s #47 allows the optimal 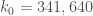 .
.
I haven’t updated yet, but this already gives us a prime gap of 4,982,086.
yet, but this already gives us a prime gap of 4,982,086.
I updated the mathematica notebook that did that calculation at http://tqft.net/misc/finding%20k_0.nb ; perhaps someone could check it. (Although the fact that it agrees with the optimal bound ignoring is I guess reasonable evidence I didn’t mess anything up.)
is I guess reasonable evidence I didn’t mess anything up.)
The value of is now sufficiently low that more techniques for optimizing the admissible sequence are becoming plausible. We know there’s not a huge amount of juice to be squeezed there, however. If
is now sufficiently low that more techniques for optimizing the admissible sequence are becoming plausible. We know there’s not a huge amount of juice to be squeezed there, however. If  ever comes all the way down to 342 (we’re already an order of magnitude ahead; why not another 3) then the best answers are known.
ever comes all the way down to 342 (we’re already an order of magnitude ahead; why not another 3) then the best answers are known.
Tim reminded me to optimize again! For
again! For 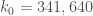 ,
,  suffices, giving a bound of 4,802,222.
suffices, giving a bound of 4,802,222.
Some small thoughts regarding optimising the admissible tuples:
1. One could modify the Richards (or more precisely Hensley-Richards) example by looking at asymmetric tuples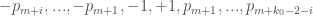 , as one might be able to get a bit of mileage out of fluctuations in gaps between primes near
, as one might be able to get a bit of mileage out of fluctuations in gaps between primes near  . But this is going to be a fairly small improvement I think (maybe improving
. But this is going to be a fairly small improvement I think (maybe improving  by a couple hundred or so).
by a couple hundred or so).
2. It is conceivable that with a Hensley-Richards tuple that there are some additional elements that one could add to the tuple that do not destroy admissibility and do not increase the diameter of the tuple. Presumably one could check for the explicit example of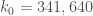 , $m = 5,553$ whether there is any “greedy” example to take here?
, $m = 5,553$ whether there is any “greedy” example to take here?
3. While a pure greedy algorithm might not be so efficient, a hybrid greedy algorithm might make sense: starting from a given interval, sieve out some explicit residue classes (e.g. or
or  for various primes
for various primes  to force admissibility in these moduli, and then run a greedy algorithm to gain admissibility in all the other relevant moduli (removing residue classes that delete as few elements from the sifted set as possible). I guess one should read the Gordon-Rodemich paper that Christian pointed to as they seem to have already experimented along these lines.
to force admissibility in these moduli, and then run a greedy algorithm to gain admissibility in all the other relevant moduli (removing residue classes that delete as few elements from the sifted set as possible). I guess one should read the Gordon-Rodemich paper that Christian pointed to as they seem to have already experimented along these lines.
“This project is curiously addictive” – T.Tao, May 31
Addictive number theory?
As the above link indicates, I’ve posted a proposal for a Polymath project to systematically optimise the bound on prime gaps and to improve the understanding of the mathematics behind these results. Please feel free to contribute your opinion on that post!
Following up on David’s suggestion to post source code, above, my code is starting to appear at
https://github.com/semorrison/polymath8
For now it just has the code to search for Richards-Henley sequences (i.e. minimizing as I did many times in the above comment thread), but I’ll add more later.
as I did many times in the above comment thread), but I’ll add more later.
It’s a github repository, so you’re welcome to fork it, make changes, and send them back to me!
As somebody who dropped out of mathematics decades ago (and can barely follow the outlines of arguments and improvements being made here), I can attest that the addictive quality of these sorts of incremental optimizations is exactly that of some types of computer programming.
The primary and sad difference is that I have been paid an obscene amount of money over the years for improving the constant factors hidden inside “Big O” notation while doing no deep thinking at all.
That said, this is all immense fun to follow, and I thank you all for the vicarious pleasure of following along.
Signed,
Polymath Groupie
Hi, I hope it’s not too late to join the party.
Following suggestion 1 of post 53, I get a bound of 4,801,744 using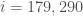 , with
, with 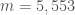 and
and 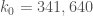 .
.
Only a small improvement, but still worth doing.
@Andrew, that’s great! Can you post your code somewhere? How many values of did you try before hitting that one?
did you try before hitting that one?
A few people have asked me how they could get involved in finding narrow admissible sets. I think there’s plenty to do, and much of it is quite easy if you know how to program!
Here’s a few:
1. Produce a table of optimal m’s for all (or at least some) k’s up to 341640.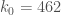 will one day become relevant, which is just beyond the end of their exhaustive table, but they give an upper bound on width of 3289. Perhaps this can be improved?
will one day become relevant, which is just beyond the end of their exhaustive table, but they give an upper bound on width of 3289. Perhaps this can be improved?
2. Systematically explore Terry’s suggestion #1 above, already
successfully implemented by Andrew Sutherland comment #60,
to get a new best prime gap.
3. Think up ways to take an “almost admissible” set, and make it
admissible while preserving width. I have one such trick, which I’ll
write about soon.
4. Push the exhaustive table at http://www.opertech.com/primes/k-tuples.html out a little further. There’s a tiny chance
I wrote a small program in Python based on Scott’s work in Scala that is available at https://github.com/avi-levy/dhl
At the moment, the code has not been optimized and I am trying to improve this.
If anyone has ideas for suggestions/improvements, don’t hesitate to contribute!
A very important optimization is to remember the last prime that
failed (for the previous value of m), and to try that first. If that
one looks okay, you should start by checking slightly higher primes.
This is what’s going on at
https://github.com/avi-levy/dhl/blob/master/dhl.py#L7
(It also sets up searching for bad primes in parallel.)
@Avi, also, I think you have a slight bug here: https://github.com/avi-levy/dhl/blob/master/dhl.py#L7
You still need to check the prime that has the same length as your sequence (almost surely it will be okay, but still). It’s only primes strictly longer than your sequence which are safe.
Scott, why is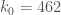 important, rather than some other small number currently out of reach?
important, rather than some other small number currently out of reach?
@David, oh, just Terry’s remark:
however I suspect http://terrytao.wordpress.com/2013/06/04/online-reading-seminar-for-zhangs-bounded-gaps-between-primes/#comment-232633 amounts to an explanation of why that result isn’t in fact going to be usable.
@Scott, I checked all values of starting from
starting from  , which corresponds to the symmetric case. The value
, which corresponds to the symmetric case. The value 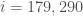 is optimal for
is optimal for 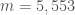 .
.
But I realized that there is no reason to stick with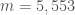 once you switch to an asymmetric sequence. Allowing both
once you switch to an asymmetric sequence. Allowing both  and
and  to vary yields a more substantial improvement.
to vary yields a more substantial improvement.
Using and
and  with
with 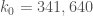 I get the bound 4,788,240.
I get the bound 4,788,240.
My code is a bit disorganized at the moment, but tomorrow I will try to clean it up and post it.
Following the references to the Gordon-Rodemich article that Christian mentioned earlier ([GR1998] on the wiki) I found a 2001 article by Clark and Jarvis http://www.ams.org/journals/mcom/2001-70-236/S0025-5718-01-01348-5/S0025-5718-01-01348-5.pdf which looks very relevant. Among other things, he computes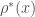 (the size of the largest admissible set in an interval of size x) up to
(the size of the largest admissible set in an interval of size x) up to  , and Table 5 has some constructions for x of the order of magnitude that we care about (using the latest record, we’re interested in x near 4,788,240. Extrapolating from this table, he seems to indicate that a construction of Schinzel would get a lower bound for
, and Table 5 has some constructions for x of the order of magnitude that we care about (using the latest record, we’re interested in x near 4,788,240. Extrapolating from this table, he seems to indicate that a construction of Schinzel would get a lower bound for 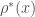 that is only a few thousand less than
that is only a few thousand less than 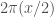 ; for
; for  , this is 351,788, which is a fair bit larger than
, this is 351,788, which is a fair bit larger than 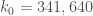 . This suggests that we should try implementing the Schinzel construction as it could be competitive with the Hensley-Richards construction. I don’t fully understand the Schinzel construction yet (I’m having trouble finding a precise description of this construction), but it appears that one starts with the integers from 1 to x, then deletes (or sifts out) all the residue classes -1 mod p for all p up to some threshold s to be optimised in later, and then apply the greedy algorithm for the primes above s (sifting out the progression that removes the minimal number of elements).
. This suggests that we should try implementing the Schinzel construction as it could be competitive with the Hensley-Richards construction. I don’t fully understand the Schinzel construction yet (I’m having trouble finding a precise description of this construction), but it appears that one starts with the integers from 1 to x, then deletes (or sifts out) all the residue classes -1 mod p for all p up to some threshold s to be optimised in later, and then apply the greedy algorithm for the primes above s (sifting out the progression that removes the minimal number of elements).
OK, I found a good description of the Schinzel sieve in Section 4 of the Hensley-Richards paper http://matwbn.icm.edu.pl/ksiazki/aa/aa25/aa2548.pdf . The simplest version of the sieve is as follows: start with {1,…,x}, throw out all the _odd_ numbers (leaving only the even numbers), then toss out all the multiples of for some m to optimise over. If we had tossed out all the even numbers instead, then we would get the usual Sieve of Eratosthenes: primes larger than
for some m to optimise over. If we had tossed out all the even numbers instead, then we would get the usual Sieve of Eratosthenes: primes larger than  . (In principle we could also get products of such primes, but in practice our numbers are such that these products are too big to appear.) But with the odd numbers tossed out, what we get instead are numbers of the form
. (In principle we could also get products of such primes, but in practice our numbers are such that these products are too big to appear.) But with the odd numbers tossed out, what we get instead are numbers of the form 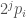 with
with 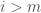 and
and  , and this is slightly denser (asymptotically, it should be denser than Hensley-Richards). More generally, we can throw out the residue classes 1 mod p (or -1 mod p, if one prefers) for all small primes
, and this is slightly denser (asymptotically, it should be denser than Hensley-Richards). More generally, we can throw out the residue classes 1 mod p (or -1 mod p, if one prefers) for all small primes 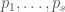 , then throw out 0 mod p for the medium primes
, then throw out 0 mod p for the medium primes 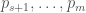 , with s and m chosen so that the resulting set is admissible.
, with s and m chosen so that the resulting set is admissible.
I am amazed not only by your mathematical abilities, but also by your ability to find mathematical resources from such obscure corners of the internet…
Here are three comments on dense prime constellations:
(Part 1 was posted before, see comment at the end).
1) The paper by Gordon and Rodemich “Dense admissible sets”
has some useful information.
http://www.ccrwest.org/gordon/ants.pdf
This paper and also Hensley and Richards (“Primes in intervals”)
matwbn.icm.edu.pl/ksiazki/aa/aa25/aa2548.pdf
both mention an observation of Schinzel on a variant of the sieve of Eratosthenes.
While one usually sieves the class , for
, for 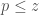 , one now sieves the class
, one now sieves the class 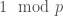 , for
, for
 and the class
and the class  for
for 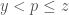 .
.
It seems that one can increase a dense cluster of primes from about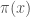 to
to  , where
, where  is larger than in
is larger than in![[-x/2,x/2]](https://s0.wp.com/latex.php?latex=%5B-x%2F2%2Cx%2F2%5D&bg=ffffff&fg=444444&s=0&c=20201002) .
.
the Hensley-Richards trick using the interval
(For details see the paper by Gordon and Rodemich).
As all this influences only the second order term,
the improvement coming from here is limited.
2) But it still leads to some small improvement, and thus a new record: I was able to implement this type of improvement, with some additional refinement, as follows:
![[1; 5,080,000]](https://s0.wp.com/latex.php?latex=%5B1%3B+5%2C080%2C000%5D&bg=ffffff&fg=444444&s=0&c=20201002) .
. (as recommended implicitly by Gordon and Rodemich)
(as recommended implicitly by Gordon and Rodemich) should be of size larger than
should be of size larger than
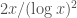 .
.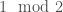 (so that all remaining classes are even!),
(so that all remaining classes are even!), for
for  .
.
a)
I choose the interval slightly larger,
as I will discard the first part of it later:
Choose
and notice that
I do this a bit different:
I sieve
and
369,760 integers survived this sieve process.
Then modulo
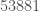 . As I do not have to do this modulo all primes,
. As I do not have to do this modulo all primes,
I tested if the set occupies all classes.
If mod p all classes are occupied I sieve the class 0 mod these primes.
(This was the case for only 1879 of these 3200 primes, the largest being
there is some saving, which seems empirically larger than the choice
of the class 1 mod 2.)
357,138 integers survived this second sieving,![[1; 5,080,000]](https://s0.wp.com/latex.php?latex=%5B1%3B+5%2C080%2C000%5D&bg=ffffff&fg=444444&s=0&c=20201002) one sees that the sequence starts sparse
one sees that the sequence starts sparse
so there is some room for shifting the interval:
If one uses the interval
(powers of 2) powers of 2.
A quite good interval is the last 341,640 of the integers.
a slightly better starts at
{352634, 352642, 352654, 352658,…
5077634, 5077642, 5077648, 5077652, 5077654}
The gap (and therfore the new record) is $\latex 4,725,021$.1
Then modulo larger primes up to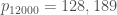
I tested if the set occupies all classes, and no further
example was found where the set occupies all classes.
(This gets increasingly unlikely, but actually,
for a final proof I would need to extend this test! As these numbers
still go down, it did not seem appropriate to put too much effort into
this, at the time being).
Some optimisation seems possible, but probably it's more interesting to see
if a change of search strategy helps more, (see point 3).
3) Apart from a complete search, of all tuples
 of the main term.
of the main term.
k tuples in an interval of size about 5,000,000,
which would seem hopeless, it would be interesting,
if the search space of sifted sets with just one arbitrary class
removed modulo each prime, but not necessarily the class 1 or 0,
contains better examples.
Observe that this might heuristically give
surviving integers and so
potentially gains a factor of
In other words, one could try different variants of Schinzel's modification.
While I expect that sieving the class 0 for most primes is really good, I do not understand why
it must be the best.
Historical comment:
I had initially written this on June 3rd, when the record was above 13 million,
and I could push it down to 12,870,557.
I posted it, and it was eaten up by the spam filter,
I intended to post it in three shorter bits again,
and the first part appeared above.
The next day the record was down to $k=341,640$,
I rerun my calculations and updated part 2, when I wanted to post
it I saw on Terry's blog a note that Scott had improved the record
to H(341,640) \leq 4,693,068. However, meanwhile on Scott's blog
the record seems to be still weaker and I believe the "4,693,068" may be a typo on Terry's blog (this was in the first long entry), as the second entry links to the polymath record
Christian: sorry about the typo – not sure how that happened, but I belatedly fixed it. So it seems the hybrid Schinzel/greedy sieve of Gordon-Rodemich may well be the best strategy so far.
A heads up – we have a significant advance on the “optimising k_0” front, it is likely to drop soon by an order of magnitude from 341,640 to something close to 34,429. This is not yet confirmed because there is a technical error term which should be exponentially small but this needs to be checked. But this confirmation should be forthcoming.
which should be exponentially small but this needs to be checked. But this confirmation should be forthcoming.
A lower would certainly be most welcome!
would certainly be most welcome!
In the meantime, taking a brute force approach along the lines of Elsholtz’s post 72, if I sieve the interval![[1,5064638]](https://s0.wp.com/latex.php?latex=%5B1%2C5064638%5D&bg=ffffff&fg=444444&s=0&c=20201002) of odd numbers and then
of odd numbers and then  for increasing primes
for increasing primes 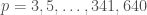 for which all residue classes are still occupied, I wind up sieving a total of 4,535 residue classes (including
for which all residue classes are still occupied, I wind up sieving a total of 4,535 residue classes (including  ). The first prime that I don’t sieve a residue class for is $p_{3450}=33,113$, and the last prime that I do sieve a residue class for is $p_{5415}=53,087$.
). The first prime that I don’t sieve a residue class for is $p_{3450}=33,113$, and the last prime that I do sieve a residue class for is $p_{5415}=53,087$.
Taking the last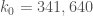 unsieved integers that remain, starting with 347,078 and ending with 5,064,638 yields an admissable sequence with diameter 4,717,560, which I believe is a new record.
unsieved integers that remain, starting with 347,078 and ending with 5,064,638 yields an admissable sequence with diameter 4,717,560, which I believe is a new record.
As noted by Elsholtz, one might expect to do slightly better by not necessarily always sieving , but so far I have not found a situation where this helps. One might sieve intervals that also include negative numbers, but the downside of doing so is that there is a very sparse region around 0 that one must trade off against increased density at the ends of the interval.
, but so far I have not found a situation where this helps. One might sieve intervals that also include negative numbers, but the downside of doing so is that there is a very sparse region around 0 that one must trade off against increased density at the ends of the interval.
For what it’s worth, if I apply the procedure in post 74 using and the interval
and the interval ![[1,419984]](https://s0.wp.com/latex.php?latex=%5B1%2C419984%5D&bg=ffffff&fg=444444&s=0&c=20201002) , taking the last
, taking the last  of the unsieved integers yields an admissable sequence beginning with 22,874 and ending with 419,984 that has diameter 397,110.
of the unsieved integers yields an admissable sequence beginning with 22,874 and ending with 419,984 that has diameter 397,110.
If anyone wants to play with sieving to obtain admissible sets feel free to use my code at https://github.com/vit-tucek/admissible_sets
I was able to gain additional ground using a “greedy-greedy” approach. For a suitably chosen interval![[1,B]](https://s0.wp.com/latex.php?latex=%5B1%2CB%5D&bg=ffffff&fg=444444&s=0&c=20201002) , first sieve
, first sieve 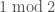 and
and  for primes
for primes  . Then for all primes
. Then for all primes  in the interval
in the interval ![[\sqrt{B},k_0]](https://s0.wp.com/latex.php?latex=%5B%5Csqrt%7BB%7D%2Ck_0%5D&bg=ffffff&fg=444444&s=0&c=20201002) , determine the residue class
, determine the residue class  with the fewest unsieved integers in it (in case of ties, minimize
with the fewest unsieved integers in it (in case of ties, minimize ![a\in[0,p-1]](https://s0.wp.com/latex.php?latex=a%5Cin%5B0%2Cp-1%5D&bg=ffffff&fg=444444&s=0&c=20201002) ). It may be that there are no unsieved integers in this residue class, in which case move on to the next prime
). It may be that there are no unsieved integers in this residue class, in which case move on to the next prime  , but otherwise sieve
, but otherwise sieve  .
.
Applying this with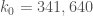 using
using  and taking the last
and taking the last  unsieved integers left in
unsieved integers left in ![[1,B]](https://s0.wp.com/latex.php?latex=%5B1%2CB%5D&bg=ffffff&fg=444444&s=0&c=20201002) yields an admissable sequence starting with 82,923 and ending with 4.739,222 that has diameter 4,656,298.
yields an admissable sequence starting with 82,923 and ending with 4.739,222 that has diameter 4,656,298.
A total of only 4,413 residue classes get sieved. The first nonzero residue class is for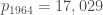 , the least prime for which no residue class is sieved is
, the least prime for which no residue class is sieved is  , and the largest prime for which a residue class is sieved is
, and the largest prime for which a residue class is sieved is  .
.
Playing the same game with the provisional using
using  yields an admissable sequence starting with 9,742 and ending with 399,664 that has diameter 389,922.
yields an admissable sequence starting with 9,742 and ending with 399,664 that has diameter 389,922.
Here is an update on the previous comment that maybe
one should not always sieve 0 mod p (as in Eratosthenes).
I now sieve 1 mod 2 (leaving the even integers) as suggested by Schinzel, and then I sieve the class Floor(p/2) modulo p.
With k=341640, sieving modulo all of the first 3800 primes in the interval [1 to 3 million] and then sieving modulo those primes which occupy all classes, (currently, I do not dynamically update this).
I get 341,640 integers in [164,042; 2,999,700], i.e. an interval size
2,835,729.
I am sure Andrew can optimise these parameters quickly.
As this actually dropped by a factor, it seems that the main term of x/log is affected and one could wonder whether this means anything for the theory of sieves.
@Christian: I’m not sure I follow you. If I sieve [1,3,000,000] of integers congruent to floor(p/2) mod p for the first 3800 primes (which I note includes sieving 1 mod 2), I am left with only 204,446 survivors, even before checking residue classes for any larger primes.
The list of survivors after sieving just the first 3800 primes begins 17,898, 17,900, 17,904, 17,918, 17,934 and ends 2,999,940, 2,999,954, 2,999,960, 2,999,966, 2,999,996.
Am I missing something here?
In general, always sieving floor(p/2) mod p seems to do worse than always sieving 0 mod p (I actually need to use an interval bigger than [1,5080000] just to get 341,640 survivors). Using the greedy-greedy approach described in 77 does work better — even though it greedily chooses to sieve 0 mod p for the first few thousand primes, it sieves nonzero residue classes in most of the remaining cases.
Just a mini-remark on Andrew’s greedy-greedy approach. In this case it does seem useful to start from (slightly asymmetric) intervals around 0, at least in case $k_0 = 34429$). E.g. starting from the interval $[-170000,220000]$, sieving $1$ mod $2$, $0$ mod $p$ for $p$ up to $p=443$ and then applying the greedy trick yields a diameter of $388284$. I didn’t try this for $k_0=341640$.
Shifting the sieving interval for the greedy-greedy algorithm given in post 77 gives further improvements. For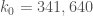 using the interval [-2289488, 23181174] yields an admissable sequence that starts and ends with the endpoints of the interval, with diameter 4,607,490.
using the interval [-2289488, 23181174] yields an admissable sequence that starts and ends with the endpoints of the interval, with diameter 4,607,490.
For the provisional using the interval [-189556,198754] similarly gives an admissable sequence with diameter 388,310.
using the interval [-189556,198754] similarly gives an admissable sequence with diameter 388,310.
Just a quick note that we have now confirmed that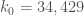 is permitted over at http://terrytao.wordpress.com/2013/06/03/the-prime-tuples-conjecture-sieve-theory-and-the-work-of-goldston-pintz-yildirim-motohashi-pintz-and-zhang , and so you guys are free to use this value to get a new value of H. :)
is permitted over at http://terrytao.wordpress.com/2013/06/03/the-prime-tuples-conjecture-sieve-theory-and-the-work-of-goldston-pintz-yildirim-motohashi-pintz-and-zhang , and so you guys are free to use this value to get a new value of H. :)
@Wouter: Hi Wouter! I see our posts crossed. For I clearly made the interval too symmetric (as with the RH sequences, some asymmetry seems to help). But using the interval [-169844,219160] gives an admissable sequence with diameter 388,248 (last sequence entry is 218,404), a further slight improvement.
I clearly made the interval too symmetric (as with the RH sequences, some asymmetry seems to help). But using the interval [-169844,219160] gives an admissable sequence with diameter 388,248 (last sequence entry is 218,404), a further slight improvement.
I’m sure there are still gains to be had by shifting the interval around in the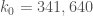 case.
case.
@Terry: That’s fantastic news, thanks! With this small it is should be feasible to do some more sophisticated combinatorial optimizations, rather than sticking to a purely greedy approach.
this small it is should be feasible to do some more sophisticated combinatorial optimizations, rather than sticking to a purely greedy approach.
After further tweaking of the interval with , using [-185662,202456] with the greedy-greedy algorithm yields an admissable sequence with diameter 388,118 that starts and ends on the end points.
, using [-185662,202456] with the greedy-greedy algorithm yields an admissable sequence with diameter 388,118 that starts and ends on the end points.
Andrew, I implemented the algorithm you pointed out in comment 77 and seem to get diam(H) = 371606 where |H| = 34429 and H is admissible.
I will post my code shortly to Github (https://github.com/avi-levy/dhl) so others may verify correctness.
The file is called sutherland.py
aviwlevy: My code produced
H = np.arange(2,399664)
H,primes = greedy_greedy(H,H[-1]-H[0])
—>
diameter: 399660 length: 34749 admissible: True
best diameter of length 34429 is: 389940
But I haven’t checked if we have the same bounds in various places. I.e. there could be some off by one errors. Anyway, it’s close enough and it seems that Andrew’s method works.
@aviwlevy: I took a quick look at your code, and it appears in your implementation that there are a few places where you are using the index i but should be using the value low+2*i corresponding to the element of the interval indexed by i. Also, the interval [-185662,202456] is closed, but I think you are treating it as half open. In any case, the sequence output by your program is not admissable, it hits every congruence class mod 641, for example.
I have to run now, but tomorrow I can take a closer look.
In the meantime, I have posted the admissable sequence with diameter 388,188 for k0=34429 here:
http://math.mit.edu/~drew/admissable.txt
I will post my own C code once I have a chance to clean it up (it keeps changing!), but at least everyone can see the sequence and easily verify for themselves (e.g. using code posted elsewhere in this thread) that it is indeed admissable and of the size and diameter claimed (verifying the correctness of the results is a lot easier than verifying the correctness of the code in any case).
I’ve just posted a new thread at https://sbseminar.wordpress.com/2013/06/05/more-narrow-admissible-sets/. Let’s continue there. I know we haven’t quite reached 100 comments, but as I’m about to spend a long time on planes it seemed better to do it sooner rather than later.
Is the following true?
————————————————–
Primes are uniformly distributed
Let p, r, n are positive integers with p>1.
U(p, r, n) denotes the number of primes less than n that are equal to r (mod p).
For any prime p and pair of integers r1, r2 between 1 and p-1, we have:
The ratio U(p,r1,n) / U(p,r2,n) has limit 1 as n goes to infinity.