A few weeks ago, I e-mailed Will Sawin excitedly to tell him that I could extend the new bounds on three-term arithmetic progression free subsets of 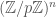 to
to  . Will politely told me that I was the third team to get there — he and Eric Naslund already had the result, as did Fedor Petrov. But I think there might be some expository benefit in writing up the three arguments, to see how they are all really the same trick underneath.
. Will politely told me that I was the third team to get there — he and Eric Naslund already had the result, as did Fedor Petrov. But I think there might be some expository benefit in writing up the three arguments, to see how they are all really the same trick underneath.
Here is the result we are proving: Let 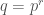 be a prime power and let
be a prime power and let 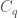 be the cyclic group of order
be the cyclic group of order  . Let
. Let 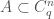 be a set which does not contain any three term arithmetic progression, except for the trivial progressions
be a set which does not contain any three term arithmetic progression, except for the trivial progressions 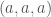 . Then
. Then
![\displaystyle{|A| \leq 3 | \{(m^1, m^2, \ldots, m^n) \in [0,q-1]^n : \sum m^i \leq n(q-1)/3 \}|.}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%7CA%7C+%5Cleq+3+%7C+%5C%7B%28m%5E1%2C+m%5E2%2C+%5Cldots%2C+m%5En%29+%5Cin+%5B0%2Cq-1%5D%5En+%3A+%5Csum+m%5Ei+%5Cleq+n%28q-1%29%2F3+%5C%7D%7C.%7D&bg=ffffff&fg=444444&s=0&c=20201002)
The exciting thing about this bound is that it is exponentially better than the obvious bound of  . Until recently, all people could prove was bounds like
. Until recently, all people could prove was bounds like  , and this is still the case if is not a prime power.
, and this is still the case if is not a prime power.
All of our bounds extend to the colored version: Let 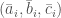 be a list of
be a list of  triples in
triples in 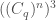 such that
such that  , but
, but 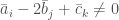 if
if 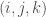 are not all equal. Then the same bound applies to . To see that this is a special case of the previous problem, take
are not all equal. Then the same bound applies to . To see that this is a special case of the previous problem, take 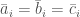 . Once the problem is cast this way, if is odd, one might as well define
. Once the problem is cast this way, if is odd, one might as well define 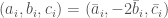 , so our hypotheses are that
, so our hypotheses are that 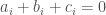 but
but 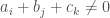 if are not all equal. We will prove our bounds in this setting.
if are not all equal. We will prove our bounds in this setting.
My argument — Witt vectors
I must admit, this is the least slick of the three arguments. The reader who wants to cut to the slick versions may want to scroll down to the other sections.
We will put an abelian group structure 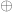 on the set
on the set  which is isomorphic to , using formulas found by Witt. I give an example first: Define an addition on
which is isomorphic to , using formulas found by Witt. I give an example first: Define an addition on  by
by
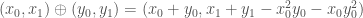
The reader may enjoy verifying that this is an associative addition, and makes into a group isomorphic to  . For example,
. For example, 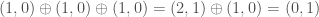 and
and 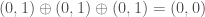 .
.
In general, Witt found formulas
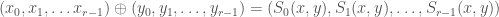
such that becomes an abelian group isomorphic to . If we define 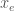 and
and  to have degree
to have degree 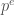 , then
, then  is homogenous of degree . (Of course, Witt did much more: See Wikipedia or Rabinoff.)
is homogenous of degree . (Of course, Witt did much more: See Wikipedia or Rabinoff.)
Write
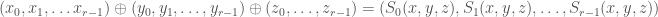 .
.
and set
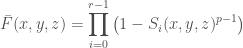 .
.
For example, when 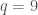 , we have
, we have
 .
.
So 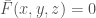 if and only if
if and only if 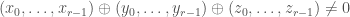 in .
in .
We now work with 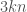 variables,
variables,  ,
, 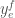 and
and 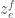 , where
, where  and
and  . Consider the polynomial
. Consider the polynomial
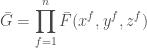 .
.
Here each 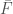 is a polynomial in
is a polynomial in  variables.
variables.
So 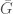 is a polynomial on
is a polynomial on 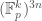 . We identify this domain with
. We identify this domain with 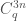 . Then
. Then 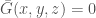 if and only if
if and only if 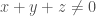 in the group
in the group 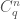 .
.
We define the degree of a monomial in the , and by setting 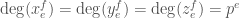 . In this section, “degree” always has this meaning, not the standard one. The degree of is ; the degree of is
. In this section, “degree” always has this meaning, not the standard one. The degree of is ; the degree of is 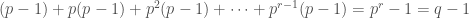 and the degree of is
and the degree of is 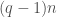 .
.
From each monomial in , extract whichever of 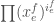 ,
, 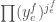 or
or 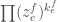 has lowest degree. We see that we can write
has lowest degree. We see that we can write
where 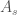 ,
, 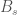 and
and  are monomials of degree
are monomials of degree 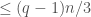 .
.
The now-standard argument (I like Terry Tao’s exposition) shows that is bounded by three times the number of monomials 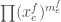 of degree . One needs to check that the argument works when the “degree” of a variable need not be
of degree . One needs to check that the argument works when the “degree” of a variable need not be  , but this is straightforward.
, but this is straightforward.
Except we have a problem! There are too many monomials. To solve this issue, let  be the polynomial obtained from by replacing every monomial
be the polynomial obtained from by replacing every monomial 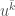 by
by 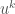 where
where 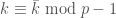 with
with 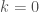 if
if  and
and 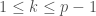 if
if  . So coincides with as a function on
. So coincides with as a function on  , but uses smaller monomials. For example, the reader who multiplies out the expression for when will find a term
, but uses smaller monomials. For example, the reader who multiplies out the expression for when will find a term 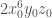 . In , this is replaced by
. In , this is replaced by 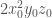 . The polynomial does not have the nice factorization of , but it is much smaller. For example, when , has
. The polynomial does not have the nice factorization of , but it is much smaller. For example, when , has 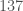 nonzero monomials and has
nonzero monomials and has 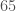 . Replacing by can only lower degree, so
. Replacing by can only lower degree, so 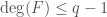 . Now rerun the argument with
. Now rerun the argument with 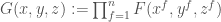 . Our new bound is three times the number of monomials of degree , with the additional condition that all exponents
. Our new bound is three times the number of monomials of degree , with the additional condition that all exponents 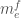 are
are  .
.
Now, the monomial  has degree
has degree 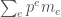 . Identify
. Identify ![[0,p-1]^r](https://s0.wp.com/latex.php?latex=%5B0%2Cp-1%5D%5Er&bg=ffffff&fg=444444&s=0&c=20201002) with
with ![[0,q-1]](https://s0.wp.com/latex.php?latex=%5B0%2Cq-1%5D&bg=ffffff&fg=444444&s=0&c=20201002) by sending
by sending 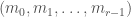 to
to 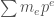 . We can thus think of
. We can thus think of ![[0,p-1]^{rn}](https://s0.wp.com/latex.php?latex=%5B0%2Cp-1%5D%5E%7Brn%7D&bg=ffffff&fg=444444&s=0&c=20201002) as
as ![[0,q-1]^n](https://s0.wp.com/latex.php?latex=%5B0%2Cq-1%5D%5En&bg=ffffff&fg=444444&s=0&c=20201002) . We get the bound
. We get the bound ![N \leq 3 | \{(m^1, m^2, \ldots, m^n) \in [0,q-1]^n : \sum m^i \leq n(q-1)/3 \}|](https://s0.wp.com/latex.php?latex=N+%5Cleq+3+%7C+%5C%7B%28m%5E1%2C+m%5E2%2C+%5Cldots%2C+m%5En%29+%5Cin+%5B0%2Cq-1%5D%5En+%3A+%5Csum+m%5Ei+%5Cleq+n%28q-1%29%2F3+%5C%7D%7C&bg=ffffff&fg=444444&s=0&c=20201002) , just as in the prime case.
, just as in the prime case.
Naslund-Sawin — binomial coefficients
Let’s be much slicker. Here is how Naslund and Sawin do it (original here).
Notice that, by Lucas’s theorem, the function 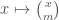 is a well defined function
is a well defined function 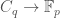 when
when  . Moreover, using Lucas again,
. Moreover, using Lucas again,
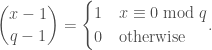
Define a function  by
by
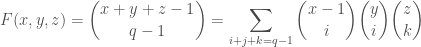
 .
.
Here we have expanded by Vandermonde’s identity and used 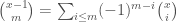 .
.
Define a function  by
by 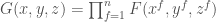 just as before. So
just as before. So 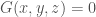 if and only if in the abelian group . Expanding
if and only if in the abelian group . Expanding 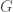 gives a sum of terms of the form
gives a sum of terms of the form 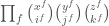 . Considering such a term to have “degree”
. Considering such a term to have “degree” 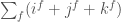 , we see that has degree
, we see that has degree  .
.
As in the standard proof, factor out whichever of 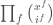 ,
,  or
or 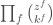 , has least degree. We obtain
, has least degree. We obtain
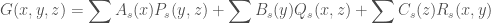
where ,  and
and  are products of binomial coefficients and, taking
are products of binomial coefficients and, taking 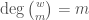 , we have
, we have 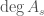 ,
, 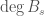 and
and 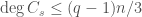 .
.
We derive the bound ![N \leq 3 | \{(m^1, m^2, \ldots, m^n) \in [0,q-1]^n : \sum m^f \leq n(q-1)/3 \}|](https://s0.wp.com/latex.php?latex=N+%5Cleq+3+%7C+%5C%7B%28m%5E1%2C+m%5E2%2C+%5Cldots%2C+m%5En%29+%5Cin+%5B0%2Cq-1%5D%5En+%3A+%5Csum+m%5Ef+%5Cleq+n%28q-1%29%2F3+%5C%7D%7C&bg=ffffff&fg=444444&s=0&c=20201002) , exactly as before.
, exactly as before.
Group rings — Petrov’s argument
I have taken the most liberties in rewriting this argument, to emphasize the similarity with the other arguments. The reader can see the original here.
Let 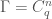 . Let
. Let 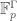 be the ring of functions
be the ring of functions 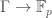 with pointwise operations, and let
with pointwise operations, and let ![\mathbb{F}_p[\Gamma]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D_p%5B%5CGamma%5D&bg=ffffff&fg=444444&s=0&c=20201002) be the group ring of
be the group ring of 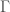 . We think of acting on by
. We think of acting on by 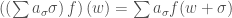 .
.
Let  ,
, 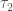 , …,
, …, 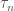 be generators for . Let
be generators for . Let  the functions annihilated by the operators
the functions annihilated by the operators 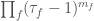 where
where 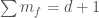 . For example,
. For example, 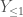 is the functions
is the functions 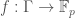 which obey
which obey 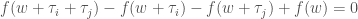 for any
for any 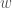 ,
,  and
and  . We think of
. We think of 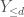 as polynomials of degree
as polynomials of degree 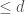 , and the dimension of is the number of monomials in
, and the dimension of is the number of monomials in  variables of total degree where each variable has degree
variables of total degree where each variable has degree 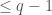 .
.
Define 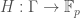 by
by 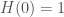 and
and  otherwise. Define
otherwise. Define 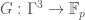 by
by  .
.
We write 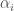 ,
,  and
and  for the generators of the three factors in
for the generators of the three factors in 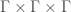 .
.
Then we have
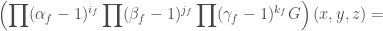
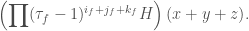
So, if 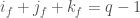 , then
, then 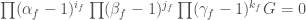 as a function on
as a function on  .
.
On the other hand, we can expand 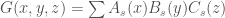 for , and in . We see that, if , then
for , and in . We see that, if , then
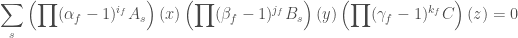 .
.
We make the familiar deduction: We can write in the form
where , and run over a basis for  .
.
Once more, we obtain the bound  .
.
Petrov’s method has an advantage not seen in the other proofs: It generalizes well to the case that is non-abelian. For any finite group , let 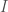 be a one-sided ideal in obeying
be a one-sided ideal in obeying 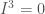 . In our case, this is the ideal generated by with
. In our case, this is the ideal generated by with 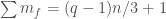 . Then we obtain a bound
. Then we obtain a bound ![N \leq 3 \dim \mathbb{F}_p[\Gamma]/I](https://s0.wp.com/latex.php?latex=N+%5Cleq+3+%5Cdim+%5Cmathbb%7BF%7D_p%5B%5CGamma%5D%2FI&bg=ffffff&fg=444444&s=0&c=20201002) for sum free sets in .
for sum free sets in .
What’s going on?
I find Petrov’s proof immensely clarifying, because it explains why the arguments all give the same bound. We are all working with functions . I write them as polynomials in  variables , Naslund and Sawin use binomial coefficients
variables , Naslund and Sawin use binomial coefficients 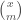 . The formulas to translate between our variables are a mess: For example, my
. The formulas to translate between our variables are a mess: For example, my 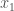 is their
is their 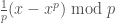 . However, we both agree on what it means to be a polynomial of degree : It means to be annihilated by
. However, we both agree on what it means to be a polynomial of degree : It means to be annihilated by  .
.
In both cases, we take the indicator function of the identity and pull it back to along the addition map. The first two proofs use explicit identities to see that the result has degree . The third proof points out this is an abstract property of functions pulled back along addition of groups, and has nothing to do with how we write the functions as explicit formulas.
I sometimes think that mathematical progress consists of first finding a dozen proofs of a result, then realizing there is only one proof. My mental image is settling a wilderness — first there are many trails through the dark woods, but later there is an open field where we can run wherever we like. But can we get anywhere beyond the current bounds with this understanding? All I can say is not yet…
![\mathbb{Q}(\cos \tfrac{2 \pi}{7} ) \cong \mathbb{Q}[x]/f(x) \mathbb{Q}[x] \cong \mathbb{Q}(\cos \tfrac{4 \pi}{7}).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BQ%7D%28%5Ccos+%5Ctfrac%7B2+%5Cpi%7D%7B7%7D+%29+%5Ccong+%5Cmathbb%7BQ%7D%5Bx%5D%2Ff%28x%29+%5Cmathbb%7BQ%7D%5Bx%5D+%5Ccong+%5Cmathbb%7BQ%7D%28%5Ccos+%5Ctfrac%7B4+%5Cpi%7D%7B7%7D%29.&bg=ffffff&fg=444444&s=0&c=20201002)
 .” I think most students probably benefit from seeing things done carefully for a term first.
.” I think most students probably benefit from seeing things done carefully for a term first. , as
, as  . We just don’t know it is that what we’ve found!
. We just don’t know it is that what we’ve found!  be an abelian group. A subset
be an abelian group. A subset  of
of 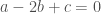 with
with  ,
,  ,
, 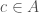 , other than the trivial solutions
, other than the trivial solutions 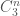 can have size at most
can have size at most 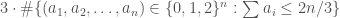 , which is
, which is 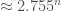 . This was the first upper bound better than
. This was the first upper bound better than 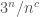 , and has set off a storm of activity on related questions.
, and has set off a storm of activity on related questions.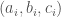 in
in 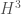 , and we see that it is free of arithmetic progressions if we have
, and we see that it is free of arithmetic progressions if we have 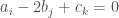 if and only if
if and only if 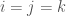 . So, if
. So, if 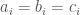 , then this is the same as a set free of three term arithmetic progressions, but the colored version allows us the freedom to set the three coordinates separately.
, then this is the same as a set free of three term arithmetic progressions, but the colored version allows us the freedom to set the three coordinates separately.  are treated separately, if
are treated separately, if 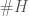 is odd, we may as well replace
is odd, we may as well replace 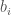 by
by  and just require that
and just require that 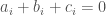 if and only if
if and only if 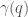 such that
such that and
and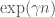 .
. ? We suspect it is the same number as in Ellenberg-Giswijt, but we don’t know!
? We suspect it is the same number as in Ellenberg-Giswijt, but we don’t know!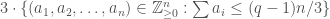 .
. 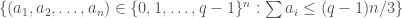 , almost all the
, almost all the  , almost all
, almost all  zeroes,
zeroes,  ones and
ones and 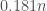 twos. The number of such
twos. The number of such 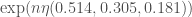 , where
, where 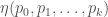 is the entropy
is the entropy 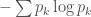 .
.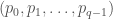 be the probability distribution on
be the probability distribution on 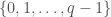 which maximizes entropy, subject to the constraint that the expected value
which maximizes entropy, subject to the constraint that the expected value  is
is 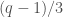 . Then almost all
. Then almost all 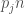 copies of
copies of 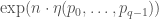 . I’ll call
. I’ll call 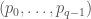 the EG-distribution.
the EG-distribution. -symmetric probability distribution on
-symmetric probability distribution on 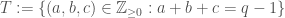 such that
such that 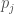 was the marginal probability that the first coordinate of
was the marginal probability that the first coordinate of 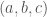 was
was 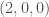 ,
, 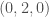 and
and 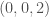 with probability
with probability 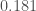 and
and 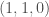 ,
, 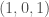 and
and 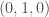 with probability
with probability 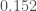 , then the resulting distribution on each of the three coordinates is the EG-distribution
, then the resulting distribution on each of the three coordinates is the EG-distribution 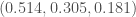 , and we can realize the growth rate of the EG bound for
, and we can realize the growth rate of the EG bound for  does not exist, then we can lower the upper bound! So, here is our result:
does not exist, then we can lower the upper bound! So, here is our result: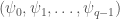 be the corresponding marginal distribution, with
be the corresponding marginal distribution, with 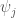 the probabilty that the first coordinate of
the probabilty that the first coordinate of 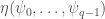 for such a
for such a  . Then
. Then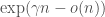 and
and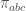 on
on 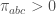 , then the marginal distribution is the EG distribution. The problem is about the distributions at the boundary; it seems hard to show that it is always beneficial to perturb inwards.
, then the marginal distribution is the EG distribution. The problem is about the distributions at the boundary; it seems hard to show that it is always beneficial to perturb inwards.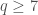 , there is more than one distribution on
, there is more than one distribution on  for some function
for some function 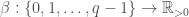 .
.  , whereas the bound for sum-free is still
, whereas the bound for sum-free is still 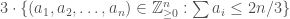 . But, as you will see, I am chasing much rougher bounds here.
. But, as you will see, I am chasing much rougher bounds here. would you vote to convict?
would you vote to convict?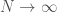 and (2) there is no way this question would have a precise round answer. As you will see, I was quite wrong.
and (2) there is no way this question would have a precise round answer. As you will see, I was quite wrong.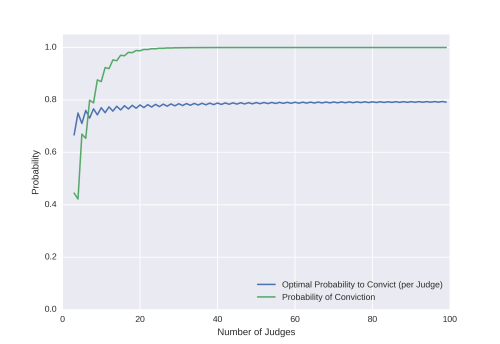
 . Can we explain this?
. Can we explain this?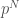 .
.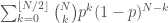 . Assuming that
. Assuming that 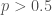 , and it certainly should be, almost all of the contribution to that sum will come from terms where
, and it certainly should be, almost all of the contribution to that sum will come from terms where 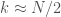 . In that case,
. In that case, 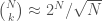 . And we’ll roughly care about
. And we’ll roughly care about 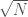 such terms. So the odds of acquittal are roughly
such terms. So the odds of acquittal are roughly  .
.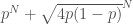 to be as small as possible. For
to be as small as possible. For  be as small as possible.
be as small as possible. :
: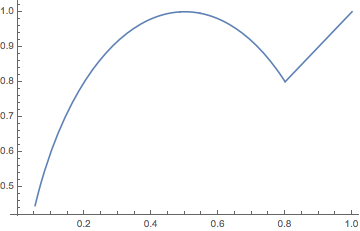
 ; that’s clearly wrong and our approximation that
; that’s clearly wrong and our approximation that 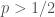 , the minimum is where
, the minimum is where 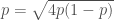 .
.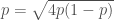 ,
,  ,
,  (since
(since 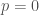 is clearly wrong),
is clearly wrong), 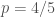 . Holy cow,
. Holy cow, 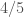 is actually right!
is actually right!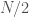 values of
values of  and the other only occurs for one value. I should have realized two things (1) the bell curve is tightly peaked, so it is really only the
and the other only occurs for one value. I should have realized two things (1) the bell curve is tightly peaked, so it is really only the 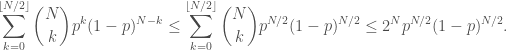
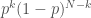 by the largest it can be.
by the largest it can be.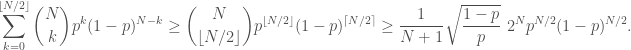
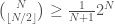 since it is the largest of the
since it is the largest of the  entries in a row of Pascal’s triangle which sums to
entries in a row of Pascal’s triangle which sums to  .
.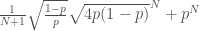 and
and 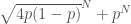 . We further use the convenient trick of replacing a
. We further use the convenient trick of replacing a 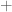 with a
with a 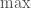 , up to bounded error to get that the odds of failure are bounded between
, up to bounded error to get that the odds of failure are bounded between  and
and  .
. 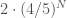 . Since
. Since 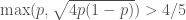 , one of the two exponentials in the first case is larger than
, one of the two exponentials in the first case is larger than 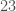 members,
members, 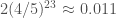 , so our upper bound predicts only a one percent probability of failure. More accurately computations give
, so our upper bound predicts only a one percent probability of failure. More accurately computations give 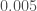 . So the whole conversation deals with the overly detailed analysis of an unlikely consequence of a bizarre hypothetical event. Fortunately, this is not a problem in the study of Talmud!
. So the whole conversation deals with the overly detailed analysis of an unlikely consequence of a bizarre hypothetical event. Fortunately, this is not a problem in the study of Talmud!