A team of six computer scientists (Lenstra, Hughes, Augier, Bos, Kleinjung and Wachter) are reporting a flaw in the way that certain SSL certificate issuers are generating RSA keys. This is getting significant online coverage at websites like NYTimes, Slashdot and BoingBoing, so I thought I’d try my hand at a low level explanation of the mathematical issues.
The goal of RSA is that you can publish a certain large number — called your public key — and anyone can then use that key to generate coded messages that only you can read. You can basically think of the RSA system like a mail drop box: Anyone can put messages into it, but only you can get them out. There many good explanations of how RSA works online, so I won’t get into the details. The essential point is that RSA keys are products of two large prime numbers. In order to make an RSA key, a computer finds two large primes and multiplies them together. The key’s owner then publishes the product, but keeps the individual primes secret. It is using these secret primes that the key’s owner can read the messages he receives. (Of course, in practice, the key’s owner will have a computer program to do this all for him: I am not suggesting that Bruce Schneier actually hauls out a piece of paper with two 300 digit primes on it everytime he reads his mail!)
If you want to read someone else’s mail, and it is protected by RSA, one method is to factor their key. Fortunately, factoring large numbers is believed to be very hard — much harder than multiplying them. So, what is the vulnerability?
The Euclidean algorithm
In elementary school, teachers may have assigned you to find the greatest common divisor of two numbers. For example, the greatest common divisor of 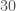
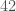
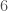


The way you would probably think of doing this is to find the prime factorizations of 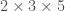


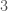
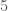
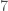

The most important thing to know about computing GCD’s is that this is the wrong way to do it. You can easily demonstrate this for yourself. Go over to Wolfram Alpha and type Factor followed by some 90 digit number. The computation will time out; this is too large to factor in the period of time that Wolfram allocates to an individual user. Now type GCD followed by two 90 digit numbers. You’ll get an answer almost instantly. (Here’s mine.) Clearly, Wolfram is doing something more clever than factoring those two numbers.
The right way to compute GCD’s is to use the Euclidean algorithm. This consists of repeatedly subtracting the smaller of your two numbers from the larger. For example, any common divisor of 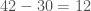

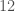



The Wikipedia link has more details. Whether or not you follow them, the key point is that factoring is hard, while GCD’s are easy.
How factorization methods work
So, one way that you might try to factor some large number 



If you just guess 
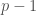



The attack
The point of the new paper is that, rather than using clever number theoretic methods to choose
When will this attack work? It will work if the RSA key manufacturers are reusing primes. For example, suppose that I have the key 


Security experts have certainly known about this issue. But it’s a tricky one to avoid. RSA certificates are being generated continuously all around the globe, so there is no way to have a database of what primes have been used. (Plus, such a database would be a huge prize for computer criminals; if you stole it, you would know exactly which prime divisors to try in a future attack!)
So the approach which is used is simply to generated random primes from a very large space, and hope that the set of primes being used is large enough. If you and I are trying to go to New York City and not see each other, we don’t have to coordinate plans. We just have to each go to a random street corner and stay put, and we will almost surely succeed.
In this case, New York is the set of all 512 bit prime numbers. (For 1024 bit RSA. There is also 2048 bit RSA, which uses even larger primes.) These are primes that are roughly 154 digits long, and there are about 
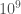

Sidenote: Some clever readers might be remembering the game where your teacher bet you that two people in the class had the same birthday. Even though there were only 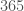


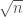

Theory versus practice
That’s how its supposed to work. Key generators choose random pairs of primes from a set of size
But, apparently, they do. Some primes, it seems, are the Times Square of 300 digit primes. In a sampling of 
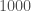
A few thoughts on solutions
What should the response be? Here I am hesitant to give ideas, because I am a mathematician, not a security expert. One approach is to figure out why these primes are getting reused. Another is to simply stay away from the key issuers which seem to have this problem most often; the paper reports that this issue is much rarer for some issuers than others. Or one could imagine testing each key against a few million preexisting keys, and regenerating it if a hit comes up.
I also wonder whether going to products of three primes might work, if these more basic methods don’t solve the problem. RSA works just fine with products of more than two primes, and it is believed, you need to find all the prime factors to break it. If we used products of three primes, then a single GCD hit would be survivable, just as long as not more than one of your primes was reused. Again, I hesitate to make suggestions, because this is an area where you should really rely on experts. But it sounds reasonable to me.

Thank you – much better than the Times.
The solution ought to be that SSL signing authorities sign certificates created by the client rather than generate the certificates themselves. Then as long as you generate your own primes using a sufficiently strong entropy source you don’t have to worry about what others are doing.
Would that really make a difference? People would still use software to do it, and most likely a couple of options would dominate the market, which would create all the same problems as before.
You are right that you could protect yourself, if you were sufficiently paranoid. But I don’t view that as a solution. Thinking in terms of e-mail, it doesn’t help for me to have a good key if my correspondents don’t. Or, thinking in terms of webcommerce, I need workable cryptography to be common enough that lots of merchants can run successful stores for me to shop at.
The real problem here is entropy generation, especially in embedded devices and other very constrained environments. (This is where virtually all of the problems occur, not on PCs or servers.) You have to have some genuine unpredictability to generate keys that can’t be guessed, so computers maintain an “entropy pool” that contains all the unpredictable things the programmers can think of, such as keystroke timings. Of course you’ve still got to process this randomness, for example by hashing, but if you don’t have enough entropy in the first place you are out of luck. The more limited your computer is, the fewer entropy sources you’ll have. So, for example, routers have much more trouble generating good keys than servers do. The good news is that the keys they generate matter less.
In principle, we could solve this problem by equipping everything with hardware random number generators. In practice, it remains to be seen what the most cost-effective solution is.
The best source of further information I know of is this blog post:
https://freedom-to-tinker.com/blog/nadiah/new-research-theres-no-need-panic-over-factorable-keys-just-mind-your-ps-and-qs